代码晨练
算法
输入输出
单组输入输出
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
#include <cstdio>
#include <cstdlib>
using namespace std;
int main()
{
int a, b, c;
scanf("%d%d", &a, &b);
c = a + b;
printf("%d", c);
return 0;
}长整型
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
#include <cstdio>
#include <cstdlib>
using namespace std;
typedef long long ll;
int main()
{
ll a, b, c;
scanf("%lld%lld", &a, &b);
c = a + b;
printf("%lld", c);
return 0;
}多组输入输出
input
4
10 5
123 234
65665 34534534
10000000 10000000
output
14
357
7234
123999999999如果知道输入多少组数据
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
#include <cstdio>
#include <cstdlib>
using namespace std;
int main()
{
int a, b, c;
int n;
scanf("%d", &n);
while (n--)
{
scanf("%d%d", &a, &b);
c = a + b;
printf("%d\n", c);
}
return 0;
}如果不知道输入多少组数据
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
#include <cstdio>
#include <cstdlib>
using namespace std;
int main()
{
int a, b, c;
while (scanf("%d%d", &a, &b) != EOF)
{
c = a + b;
printf("%d\n", c);
}
return 0;
}排序
冒泡排序
作用: 最常用的排序算法,对数组内元素进行排序
比较相邻的元素。如果第一个比第二个大,就交换他们两个。
对每一对相邻元素做同样的工作,执行完毕后,找到第一个最大值。
重复以上的步骤,每次比较次数-1,直到不需要比较
示例: 将数组 { 4,2,8,0,5,7,1,3,9 } 进行升序排序
int main() {
int arr[9] = { 4,2,8,0,5,7,1,3,9 };
for (int i = 0; i < 9 - 1; i++)
{
for (int j = 0; j < 9 - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
for (int i = 0; i < 9; i++)
{
cout << arr[i] << endl;
}
system("pause");
return 0;
}总结:
排序总轮数 = 元素个数 - 1(可以理解为,每轮确定最大的一个,只需要确定n-1个元素的位置,所以一共排n-1轮)
每轮对比的次数 = 元素个数 - 排序轮数 - 1(可以理解为剩下元素的对比次数,剩下元素有【元素个数 - 排序轮数】个,而n个元素只需要排序n-1次)
选择排序
int arr[9] = { 4,2,8,0,5,7,1,3,9 };
for (int i = 0; i < 9; i++)
{
int min = i;
for (int j = i + 1; j < 9; j++)
{
if (arr[min] > arr[j])//注意这里是arr[min]也就是目前的最小值,不是arr[i],后者不变的
{
min = j;
}
}
if (min != i)
{
int temp = arr[i];
arr[i] = arr[min];
arr[min] = temp;
}
}从第一个元素开始,往后遍历元素,找到最小(大)元素的下标,并交换值
插入排序
void insertSort(int arr[], int len)
{
for (int i = 1; i < len; i++)
{
int j = i - 1, temp = arr[i];
while (j >= 0 && arr[j] > temp)
{
arr[j + 1] = arr[j];
j--;
}
arr[j + 1] = temp;
}
}【升序】外层:从第二个元素往后遍历;内层:往前比较,前面的元素大于自己就后移一位,直到找到比自己小的第一个元素或到达边界
※希尔排序
C++
void shellSortCore(vector<int>& nums, int gap, int i)
{
int inserted = nums[i];
int j; // 插入的时候按组进行插入
for (j = i - gap; j >= 0 && inserted < nums[j]; j -= gap)
{
nums[j + gap] = nums[j];
}
nums[j + gap] = inserted;
}
void shellSort(vector<int>& nums)
{
int len = nums.size(); //进行分组,最开始的时候,gap为数组长度一半
for (int gap = len / 2; gap > 0; gap /= 2) { //对各个分组进行插入分组
for (int i = gap; i < len; ++i) { //将nums[i]插入到所在分组正确的位置上
shellSortCore(nums,gap,i);
}
}
for (auto a : nums) {
cout << a << "";
}
}C
void shellSortCore(int arr[], int gap, int i)
{
int inserted = arr[i]; int j;
for (j = i - gap; j >= 0 && inserted < arr[j]; j -= gap)
{
arr[j + gap] = arr[j];
}
arr[j + gap] = inserted;
}
void shellSort(int arr[], int len)
{
for (int gap = len / 2; gap > 0; gap /= 2)
{
for (int i = gap; i < len; i++)
{
shellSortCore(arr, gap, i);
}
}
}组大小每次减半,在每个组内进行插入排序
放到一起写,就是外层多了一个循环,然后把内层的1都换成gap
void shellSort(int arr[], int len)
{
for (int gap = len / 2; gap > 0; gap /= 2)
{
for (int i = gap; i < len; i++)
{
int temp = arr[i]; int j = i - gap;
while (j >= 0 && temp <= arr[j])
{
arr[j + gap] = arr[j];
j -= gap;
}
arr[j + gap] = temp;
}
}
}※2-路归并排序
1.递归实现
const int maxn = 100;
void merge(int A[], int L1, int R1, int L2, int R2)
{
int temp[maxn];
int i = L1, j = L2, index = 0;
while (i <= R1 && j <= R2)
{
if (A[i] <= A[j])
{
temp[index++] = A[i++];
}
else
{
temp[index++] = A[j++];
}
}
while (i <= R1) temp[index++] = A[i++];
while (j <= R2) temp[index++] = A[j++];
for (int i = 0; i < index; i++)
{
A[L1 + i] = temp[i];
}
}
void mergeSort(int A[], int left, int right)
{
if (left < right)
{
int mid = (left + right) / 2;
mergeSort(A, left, mid); //分
mergeSort(A, mid + 1, right); //分
merge(A, left, mid, mid + 1, right); //合
}
}分:分成只包含一个元素的数组
合:从只包含一个元素的两个数组(每个数组有序)开始合并,合并原理同STL中的merge
※ 时间复杂度为O(nlogn)
2.非递归实现
void mergeSort(int A[])
{
for (int step = 2; step / 2 < n; step *= 2) //如果是奇数个元素,比如9,那么step就至少为16,step > n && step / 2 < n ;
{
for (int i = 0; i < n; i += step)
{
int mid = i + step / 2 - 1;
if (mid + 1 < n) //mid < n - 1 ,如果mid = n - 1,那么mid + 1就越界了
{
merge(A, i, mid, mid + 1, min(i + step - 1, n - 1));
//sort(A + i, A + min(i + step, n));
}
//如果是sort,此处可以输出 归并排序的某一趟结束的序列
//for (int i = 0; i < 10; i++)
//{
// printf("%d", A[i]);
//}
//printf("\n");
}
}
}将递归实现扁平化,step等于2就是合的第一步,两个元素一组合起来,第二次step等于4是第合的第二步,两个有序数组合起来,每个数组有两个元素。
※快速排序
int randPartition(int A[], int left, int right)
{
int p = round(1.0 * rand() / RAND_MAX * (right - left)) + left;
swap(A[p], A[left]);
int temp = A[left];
while (left < right)
{
while (left < right && A[right] > temp) right--;
A[left] = A[right];
while (left < right && A[left] <= temp) left++; //写成小于就成死循环了,如果A[left]= temp,会陷入死循环,如果是<=,那么当A[left] = temp时,至少左指针会向右移动,可以保证元素的交换
A[right] = A[left];
}
A[left] = temp;
return left;
}
void quickSort(int A[], int left, int right)
{
if (left < right)
{
int pos = randPartition(A, left, right);
quickSort(A, left, pos - 1);
quickSort(A, pos + 1, right);
}
}① 随机选择一个元素与第一个元素交换位置
② 取出第一个元素,把大于该元素的全部放到右边,小于的全部放在左边(two pointer)
每一轮快速排序的结果是,值为temp的元素左侧的元素都小于temp,右侧的元素都大于temp
※ main函数中要设定随机数种子
※ 传入的是数组下标范围而非[0,len]
※ 快速排序的情况比较棘手,在最糟情况下,其运行时间为O(n2)。在平均情况下,快速排序的运行时间为O(nlogn)。
※堆排序
堆要满足:
① 完全二叉树 : 生成节点从上往下、从左往右依次生成
② parent > children
在堆中,通过数组存放结点,可以通过如下公式计算每一个结点的父节点、 子结点
\left\{\begin{aligned} \text { parent } & =(i-1) / 2 \\ c_1 & =2 i+1 \\ c_2 & =2 i+2 \end{aligned}\right.
求父节点向下取整,只保留整数部分
C++
void heapify(vector<int>& nums, int n, int i)//对有一定顺序的堆,当前第i个结点取根左右的最大值(这个操作称heapfiy)
{
int l = i * 2 + 1, r = i * 2 + 2;
int max = i;
if (l<n && nums[l]>nums[max])
max = l;
if (r<n && nums[r]>nums[max])
max = r;
if (max != i)
{
swap(nums[max], nums[i]);
heapify(nums, n, max);
}
}
void heapify_build(vector<int>& nums, int n)//建立大根堆,从树的倒数第二层第一个结点开始,对每个结点进行heapify操作,然后向上走
{
int temp = (n - 2) / 2;
for (int i = temp; i >= 0; i--)
heapify(nums, n, i);
for (int i = 0; i < nums.size(); i++)
cout << nums[i] << " ";
cout << endl;
}
void heapify_sort(vector<int>& nums, int n)//建立大根堆之后,每次交换最后一个结点和根节点(最大值),对交换后的根节点继续进行heapify(此时堆的最后一位是最大值,因此不用管他,n变为n-1)
{
heapify_build(nums, n);
for (int i = 0; i < n; i++)
{
swap(nums.front(), nums[n - i - 1]);
heapify(nums, n - i - 1, 0);
}
}C
void swap(int arr[], int i, int j)
{
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
//对以第i个元素为根的堆进行调整,调整的结果是每个父节点均大于两个子结点
void Heapify(int tree[], int n, int i)
{
if (i >= n) //递归出口
{
return;
}
int c1 = 2 * i + 1;
int c2 = 2 * i + 2;
int max = i;
if (c1 < n && tree[c1] > tree[max])
{
max = c1;
}
if (c2 < n && tree[c2] > tree[max])
{
max = c2;
}
if (max != i)
{
swap(tree, max, i);
Heapify(tree, n, max);
}
}
//从倒数第二层往上遍历parent并调整,调整的结果是堆中的最大值成为根,也就是大根堆
void BuildHeap(int tree[], int n)
{
int last_node = n - 1;
int parent = (last_node - 1) / 2;
for (int i = parent; i >= 0; i--) //从倒数第二层往上遍历parent
{
Heapify(tree, n, i);
}
}
void HeapSort(int tree[], int n)
{
BuildHeap(tree, n); //构建大根堆
for (int i = n - 1; i >= 0; i--)
{
swap(tree, i, 0); //交换根结点与最后一个结点
Heapify(tree, i, 0); //对前n-1个元素继续调整
}
}自顶向下(调整):调整单元二叉树
自底向上(构建):调整parent构成的单元二叉树(构建大根堆)
自顶向下(排序):调整单元二叉树(元素个数-1)
※ 堆排序分为建堆和调整堆。建堆是通过父节点和子节点两两比较并交换得到的,时间复杂度为O(n),调整堆需要交换n-1次堆顶元素,并调整堆,调整堆的过程就是满二叉树的深度logn,所以时间复杂度为O(nlogn),所以最终时间复杂度为O(nlogn)
桶排序
计数排序和基数排序的思想是桶排序,桶排序不常用,且不稳定,需要用特殊技巧使其稳定。
function bucketSort(arr, bucketSize)
{
if (arr.length === 0)
{
return arr;
}
var i;
var minValue = arr[0];
var maxValue = arr[0];
for (i = 1; i < arr.length; i++)
{
if (arr[i] < minValue)
{
minValue = arr[i]; // 输入数据的最小值
}
else if (arr[i] > maxValue)
{
maxValue = arr[i]; // 输入数据的最大值
}
}
// 桶的初始化
var DEFAULT_BUCKET_SIZE = 5; // 设置桶的默认数量为5
bucketSize = bucketSize || DEFAULT_BUCKET_SIZE;
var bucketCount = Math.floor((maxValue - minValue) / bucketSize) + 1;
var buckets = new Array(bucketCount);
for (i = 0; i < buckets.length; i++)
{
buckets[i] = [];
}
// 利用映射函数将数据分配到各个桶中
for (i = 0; i < arr.length; i++)
{
buckets[Math.floor((arr[i] - minValue) / bucketSize)].push(arr[i]);
}
arr.length = 0;
for (i = 0; i < buckets.length; i++)
{
insertionSort(buckets[i]); // 对每个桶进行排序,这里使用了插入排序
for (var j = 0; j < buckets[i].length; j++)
{
arr.push(buckets[i][j]);
}
}
return arr;
}计数排序
C++
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
// 计数排序
void CountSort(vector<int>& vecRaw, vector<int>& vecObj)
{
// 确保待排序容器非空
if (vecRaw.size() == 0)
return;
// 使用 vecRaw 的最大值 + 1 作为计数容器 countVec 的大小
int vecCountLength = (*max_element(begin(vecRaw), end(vecRaw))) + 1;
vector<int> vecCount(vecCountLength, 0);
// 统计每个键值出现的次数
for (int i = 0; i < vecRaw.size(); i++)
vecCount[vecRaw[i]]++;
// 后面的键值出现的位置为前面所有键值出现的次数之和
for (int i = 1; i < vecCountLength; i++)
vecCount[i] += vecCount[i - 1];
// 将键值放到目标位置
for (int i = vecRaw.size(); i > 0; i--) // 此处逆序是为了保持相同键值的稳定性
vecObj[--vecCount[vecRaw[i - 1]]] = vecRaw[i - 1];
}
int main()
{
vector<int> vecRaw = { 0,5,7,9,6,3,4,5,2,8,6,9,2,1 };
vector<int> vecObj(vecRaw.size(), 0);
CountSort(vecRaw, vecObj);
for (int i = 0; i < vecObj.size(); ++i)
cout << vecObj[i] << " ";
cout << endl;
return 0;
}C
void CountSort(int* a, int size)
{
//计算最大最小值
int max = a[0];
int min = a[0];
for (int i = 1; i < size; ++i)
{
if (max < a[i])
{
max = a[i]; }
if (min>a[i])
{
min = a[i];
}
}
//统计每个数出现的次数
int range = max - min + 1;
int* countArray = new int[range];
memset(countArray,0,range*sizeof(int));
for (int i = 0; i < size; ++i)
{
countArray[a[i] - min]++;
}
//重新填充原数组
int index = 0;
for (int i = 0; i < range; ++i)
{
while (countArray[i]-- > 0)
{
a[index++] = min + i;
}
}
delete[] countArray;
}统计个数,重新插入原数组
基数排序
int maxbit(int data[], int n) //辅助函数,求数据的最大位数
{
int maxData = data[0];
// 先求出最大数,再求其位数,这样有原先依次每个数判断其位数,稍微优化点。
for (int i = 1; i < n; ++i)
{
if (maxData < data[i])
maxData = data[i];
}
int d = 1;
int p = 10;
while (maxData >= p)
{
//p *= 10; // Maybe overflow
maxData /= 10;
++d;
}
return d;
/*
int d = 1; //保存最大的位数
int p = 10;
for(int i = 0; i < n; ++i)
{
while(data[i] >= p)
{
p *= 10;
++d;
}
}
return d;
*/
}
void radixsort(int data[], int n) //基数排序
{
int d = maxbit(data, n);
int *tmp = new int[n];
int *count = new int[10]; //计数器
int i, j, k;
int radix = 1;
for(i = 1; i <= d; i++) //进行d次排序,每次都是一次计数排序
{
for(j = 0; j < 10; j++)
count[j] = 0; //每次分配前清空计数器
for(j = 0; j < n; j++)
{
k = (data[j] / radix) % 10; //统计每个桶中的记录数
count[k]++;
}
for(j = 1; j < 10; j++)
count[j] = count[j - 1] + count[j]; //将tmp中的位置依次分配给每个桶
for(j = n - 1; j >= 0; j--) //将所有桶中记录依次收集到tmp中
{
k = (data[j] / radix) % 10;
tmp[count[k] - 1] = data[j];
count[k]--;
}
for(j = 0; j < n; j++) //将临时数组的内容复制到data中
data[j] = tmp[j];
radix = radix * 10;
}
delete []tmp;
delete []count;
}先排个位再排十位再排百位,有几位就排几趟
排名
① 排名定义在结构体中
struct Student
{
double score;
int r;
}
Student stu[n];
//初始化stu数组,这里省略
stu[0].r = 1;
for (int i = 1; i < n; i++)
{
if (stu[i].score == stu[i - 1].score)
{
stru[i].r = stu[i - 1].r;
}
else
{
stu[i].r = i + 1;
}
}② 直接输出排名
int r = 1;
for (int i = 0; i < n; i++)
{
if (i > 0 && stu[i].score != stu[i-1].score
{
r++;
}
printf("%d ", r);//或者stu[i].r = r;
}总结
十大排序中的稳定排序
冒泡排序(bubble sort) — O(n2)
插入排序 (insertion sort)— O(n2)
归并排序 (merge sort)— O(n log n)
十大排序中的非稳定排序
选择排序 (selection sort)— O(n2)
希尔排序 (shell sort)— O(n log n)
堆排序 (heapsort)— O(n log n)
快速排序 (quicksort)— O(n log n)
面试考察中一般问快排,选择,希尔,堆这几种非稳定排序
注意 : 帽插归稳定,其他不稳定
查找
二分查找
class Solution {
public:
int search(vector<int>& nums, int target) {
int left = 0;
int right = nums.size() - 1; // 定义target在左闭右闭的区间里,[left, right]
while (left <= right) { // 当left==right,区间[left, right]依然有效,所以用 <=
int middle = left + ((right - left) / 2);// 防止溢出 等同于(left + right)/2
if (nums[middle] > target) {
right = middle - 1; // target 在左区间,所以[left, middle - 1]
} else if (nums[middle] < target) {
left = middle + 1; // target 在右区间,所以[middle + 1, right]
} else { // nums[middle] == target
return middle; // 数组中找到目标值,直接返回下标
}
}
// 未找到目标值
return -1;
}
};判断中点和目标的大小关系,调整边界
※ 输入是有序的
数组
反转数组
两个指针first和last
大数相乘
链表
反转链表
https://leetcode.cn/problems/reverse-linked-list/
struct ListNode {
int val;
ListNode * next;
ListNode() : val(0), next(nullptr) {}
ListNode(int x) : val(x), next(nullptr) {}
ListNode(int x, ListNode * next) : val(x), next(next) {}
}
class Solution {
public:
ListNode* reverseList(ListNode* head) {
ListNode* pre = nullptr; //前一个
ListNode* cur = head;
ListNode* temp = nullptr; //后一个
while(cur) {
temp = cur->next; // 保存一下 cur的下一个节点,因为接下来要改变cur->next
cur->next = pre; // 翻转操作
// 更新pre 和 cur指针
pre = cur;
cur = temp;
}
return pre;
}
};时间复杂度: O(n)
空间复杂度: O(1)
删除链表的倒数第N个节点
https://leetcode.cn/problems/remove-nth-node-from-end-of-list/
struct ListNode {
int val;
ListNode * next;
ListNode() : val(0), next(nullptr) {}
ListNode(int x) : val(x), next(nullptr) {}
ListNode(int x, ListNode * next) : val(x), next(next) {}
}
class Solution {
public:
ListNode* removeNthFromEnd(ListNode* head, int n) {
ListNode* dummyHead = new ListNode(0);
dummyHead->next = head;
ListNode* slow = dummyHead;
ListNode* fast = dummyHead;
while(n-- && fast != NULL) {
fast = fast->next;
}
fast = fast->next; // fast再提前走一步,因为需要让slow指向删除节点的上一个节点
while (fast != NULL) {
fast = fast->next;
slow = slow->next;
}
slow->next = slow->next->next;
// ListNode *tmp = slow->next; C++释放内存的逻辑
// slow->next = tmp->next;
// delete nth;
return dummyHead->next;
}
};时间复杂度: O(n)
空间复杂度: O(1)
合并有序链表
https://leetcode.cn/problems/merge-two-sorted-lists/
struct ListNode
{
int val;
ListNode * next;
ListNode() : val(0), next(nullptr) {}
ListNode(int x) : val(x), next(nullptr) {}
ListNode(int x, ListNode * next) : val(x), next(next) {}
};
ListNode * mergeTwoLists(ListNode * list1, ListNode * list2)
{
if (list1 == nullptr) return list2;
if (list2 == nullptr) return list1;
ListNode dummyHead = ListNode();
ListNode * cur = &dummyHead;
while (list1 != nullptr && list2 != nullptr)
{
if (list1->val < list2->val)
{
cur->next = list1;
list1 = list1->next;
}
else
{
cur->next = list2;;
list2 = list2->next;
}
cur = cur->next;
}
if (list1 != nullptr) cur->next = list1;
if (list2 != nullptr) cur->next = list2;
return dummyHead.next;
}
int main()
{
ListNode * node0 = new ListNode(0);
ListNode * node1 = new ListNode(1);
ListNode * node2 = new ListNode(2);
ListNode * node3 = new ListNode(3);
ListNode * node4 = new ListNode(1);
ListNode * node5 = new ListNode(4);
node0->next = node1;
node1->next = node2;
node2->next = node3;
node3->next = nullptr;
node4->next = node5;
node5->next = nullptr;
auto node = mergeTwoLists(node0, node4);
while (node != nullptr)
{
printf("%d", node->val);
node = node->next;
}
}链表重排
https://leetcode.cn/problems/reorder-list/
注意到目标链表即为将原链表的左半端和反转后的右半端合并后的结果。
这样我们的任务即可划分为三步:
找到原链表的中点(参考「876. 链表的中间结点」)。
我们可以使用快慢指针来 O(N) 地找到链表的中间节点。
将原链表的右半端反转(参考「206. 反转链表」)。
我们可以使用迭代法实现链表的反转。
将原链表的两端合并。
因为两链表长度相差不超过 1,因此直接合并即可。
class Solution {
public:
void reorderList(ListNode* head) {
if (head == nullptr) {
return;
}
ListNode* mid = middleNode(head);
ListNode* l1 = head;
ListNode* l2 = mid->next;
mid->next = nullptr;
l2 = reverseList(l2);
mergeList(l1, l2);
}
ListNode* middleNode(ListNode* head) {
ListNode* slow = head;
ListNode* fast = head;
while (fast->next != nullptr && fast->next->next != nullptr) {
slow = slow->next;
fast = fast->next->next;
}
return slow;
}
ListNode* reverseList(ListNode* head) {
ListNode* prev = nullptr;
ListNode* curr = head;
while (curr != nullptr) {
ListNode* nextTemp = curr->next;
curr->next = prev;
prev = curr;
curr = nextTemp;
}
return prev;
}
void mergeList(ListNode* l1, ListNode* l2) {
ListNode* l1_tmp;
ListNode* l2_tmp;
while (l1 != nullptr && l2 != nullptr) {
l1_tmp = l1->next;
l2_tmp = l2->next;
l1->next = l2;
l1 = l1_tmp;
l2->next = l1;
l2 = l2_tmp;
}
}
};奇偶链表
https://leetcode.cn/problems/odd-even-linked-list/
class Solution {
public:
ListNode* oddEvenList(ListNode* head) {
if (head == nullptr) {
return head;
}
ListNode* odd = head;
ListNode * even = head->next;
ListNode* evenHead = even;
while (even != nullptr && even->next != nullptr) {
odd->next = even->next;
odd = odd->next;
even->next = odd->next;
even = even->next;
}
odd->next = evenHead;
return head;
}
};删除链表重复元素
class Solution {
public:
ListNode* deleteDuplicates(ListNode* head) {
if (!head) {
return head;
}
ListNode* dummy = new ListNode(0, head);
ListNode* cur = dummy;
while (cur->next && cur->next->next) {
if (cur->next->val == cur->next->next->val) {
int x = cur->next->val;
while (cur->next && cur->next->val == x) {
cur->next = cur->next->next;
}
}
else {
cur = cur->next;
}
}
return dummy->next;
}
};时间复杂度:O(n),其中 n是链表的长度。
空间复杂度:O(1)。
队列
循环双端队列
232. 用栈实现队列
class MyQueue
{
public:
MyQueue() {}
void push(int x) {
stack_in.push(x);
}
int pop() {
if (stack_out.empty())
{
while (!stack_in.empty())
{
stack_out.push(stack_in.top()); //注意这里不能传入pop()
stack_in.pop();
}
}
int result = stack_out.top();
stack_out.pop();
return result;
}
int peek() {
int result = pop();
stack_out.push(result);
return result;
}
bool empty() {
return stack_in.empty() && stack_out.empty();
}
stack<int> stack_in;
stack<int> stack_out;
};225. 用队列实现栈
class MyStack {
public:
queue<int> que;
/** Initialize your data structure here. */
MyStack() {
}
/** Push element x onto stack. */
void push(int x) {
que.push(x);
}
/** Removes the element on top of the stack and returns that element. */
int pop() {
int size = que.size();
size--;
while (size--) { // 将队列头部的元素(除了最后一个元素外) 重新添加到队列尾部
que.push(que.front()); //注意这里不能直接传入pop
que.pop();
}
int result = que.front(); // 此时弹出的元素顺序就是栈的顺序了
que.pop();
return result;
}
/** Get the top element. */
int top() {
return que.back();
}
/** Returns whether the stack is empty. */
bool empty() {
return que.empty();
}
};时间复杂度: pop为O(n),其他为O(1)
空间复杂度: O(n)
二叉树
验证二叉搜索树
https://leetcode.cn/problems/validate-binary-search-tree/
二叉树遍历
广度/深度搜索
哈希表
三数之和
https://leetcode.cn/problems/3sum/
动态规划
最大回文数
设计模式
单例模式
确定一个类只有一个实例
构造方法是private的,不能被外界进行实例化
该实例属于当前类的静态成员变量
而且自行实例化并向整个系统提供这个实例
提供一个当前类的静态方法向外界提供当前类的实例
根据实例化实际不同,单例模式分为两种,饿汉式是静态实列加载的时候就进行实例化,懒汉式是静态实例加载的时候不进行实例化,在第一次使用的时候进行实例化
饿汉模式
class Singleton {
private:
static Singleton* instance;
// 私有构造函数,防止外部实例化
Singleton() {}
public:
// 获取单例实例的静态方法
static Singleton* getInstance() {
return instance;
}
};
// 初始化静态成员变量
Singleton* Singleton::instance = new Singleton();懒汉模式
class Singleton {
private:
static Singleton* instance;
// 私有构造函数,防止外部实例化
Singleton() {}
public:
// 获取单例实例的静态方法
static Singleton* getInstance() {
if (instance == nullptr) {
instance = new Singleton();
}
return instance;
}
};
// 初始化静态成员变量为nullptr
Singleton* Singleton::instance = nullptr;单例模式线程安全?
工厂模式
简单工厂模式
typedef enum productType {
TypeA,
TypeB,
TypeC
} productTypeTag;
class Product {
public:
virtual void show() = 0;
virtual ~Product() = 0;
};
class ProductA :public Product {
public:
void show() {
cout << "ProductA" << endl;
}
~ProductA() {
cout << "~ProductA" << endl;
}
};
class ProductB :public Product {
public:
void show() {
cout << "ProductB" << endl;
}
~ProductB() {
cout << "~ProductB" << endl;
}
};
class ProductC :public Product {
public:
void show() {
cout << "ProductC" << endl;
}
~ProductC() {
cout << "~ProductC" << endl;
}
};
class Factory {
public:
Product* createProduct(productType type) {
switch (type) {
case TypeA:
return new ProductA();
case TypeB:
return new ProductB();
case TypeC:
return new ProductC();
default:
return nullptr;
}
}
};工厂方法模式
#include <iostream>
using namespace std;
class SingleCore
{
public:
virtual void Show() = 0; //纯虚析构既需要声明也需要实现
};
Product::~Product()
{
cout << "~Product纯虚析构" << endl;
}
//单核A
class SingleCoreA : public SingleCore
{
public:
void Show() { cout << "SingleCore A" << endl; }
};
//单核B
class SingleCoreB : public SingleCore
{
public:
void Show() { cout << "SingleCore B" << endl; }
};
class Factory
{
public:
virtual SingleCore * CreateSingleCore() = 0;
};
//生产A核的工厂
class FactoryA : public Factory
{
public:
SingleCoreA * CreateSingleCore() { return new SingleCoreA; }
};
//生产B核的工厂
class FactoryB : public Factory
{
public:
SingleCoreB * CreateSingleCore() { return new SingleCoreB; }
};
int main()
{
FactoryA fa;
fa.CreateSingleCore()->Show();
return 0;
}观察者模式
数据库
MySQL
https://www.cnblogs.com/cxx8181602/p/9525950.html
https://www.cnblogs.com/cxx8181602/p/9559197.html
八股
https://www.nowcoder.com/issue/tutorial?tutorialId=93&uuid=60c2f308109c4a7d8089a710b9ba1dab
https://app.yinxiang.com/fx/a3e526fc-e956-40a8-8b55-c5a82a2195b8
牛客题库
https://www.nowcoder.com/exam/oj?page=1&tab=SQL%E7%AF%87&topicId=199
三大范式
https://blog.csdn.net/weixin_44355591/article/details/106194714
第一范式(1NF): 确保每列的原子性(强调的是列的原子性,即列不能够再分成其他几列)。实际上,第一范式是所有关系型数据库的最基本要求。
第二范式(2NF): 是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)
第二范式要求确保表中每列与主键相关,而不能只与主键的某部分相关(主要针对联合主键),主键列与非主键列遵循完全函数依赖关系,也就是完全依赖
第三范式(3NF): 是在第二范式的基础上建立起来的。第三范式指:属性不依赖于其他非主属性
第三范式确保非主键列之间没有传递函数依赖关系,也就是消除传递依赖
日志分类
事务的ACID特性
事务具有4个特性,原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持续性(Durability)。这四个特性简称为ACID特性(ACID properities)
(1)原子性
事务是数据库的逻辑工作单位,事务中包括的诸操作要么都做,要么都不做
(2)一致性
事务执行的结果必须是使数据库从一个一致性状态变到另一个一致性状态。因此当数据库只包含成功事务提交的结果时,就说数据库处于一致性状态。
(3)隔离性
一个事务的执行不能被其他事务干扰。及一个事物的内部操作及使用的数据对其他并发事务是隔离的,并发执行的各个事务之间不能相互干扰。
(4)持久性
持久性也称永久性(Permanence),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应对其执行结果有任何影响。
事务是恢复和并发控制的基本单位,事务ACID特性遭到破坏的因素有:
(1)多个事务并行运行时,不同事物的操作交叉执行
(2)事务在运行过程中被强行停止
在第一种情况下,数据库管理系统必须保证多个事物的交叉运行不影响这些事务的原子性;在第二种情况下,数据库管理系统必须保证被强行终止的事务对数据库和其他事务没有任何影响,这就是数据库管理系统中并发控制机制和恢复机制的责任。
索引种类
(1)普通索引: 仅加速查询
(2)唯一索引: 加速查询 + 列值唯一(可以有null)
(3)主键索引: 加速查询 + 列值唯一(不可以有null)+ 表中只有一个
(4)组合索引: 多列值组成一个索引,专门用于组合搜索,其效率大于索引合并
(5)全文索引: 对文本的内容进行分词,进行搜索 (注意:目前仅有MyISAM引擎支持)锁的种类
性能优化
sql优化由4个部分,第一个是硬件和操作系统成面优化,第二个是架构设计层优化,第三个是程序配置优化,第四个是sql执行优化。
第一个从硬件和操作系统层面上来说,影响mysql性能因素主要是cpu可用内存大小、磁盘读写速度、网络带宽;从操作系统层面上来说,应用文件句柄数、操作系统的网络配置都会影响到mysql的性能优化,这部分的优化一般都是DBA或者运维完成,在硬件基础资源的优化中我们重点关注的是服务本身所承载的体量,然后提出合理的指标要求,避免出现资源浪费的一个现象
第二个架构设计层面的优化。mysql是一个磁盘io访问非常频繁的关系型数据库,在高并发和高性能的场景中,mysql数据库必然会承受巨大的并发压力,在此时的优化可以分几个部分:第一个是搭建mysql主从集群,单个mysql服务容易导致单点故障,一旦服务宕机将会导致依赖mysql应用无法响应,主从集群或者主主集群都可以去保证服务的高可用性;第二个读写分离设计,在读多少写的场景中通过读写的方案可以去避免读写冲突导致性能问题第;三个是引用分库分表的机制,通过分库可以降低单个服务器节省的一个io压力,通过分表的方式可以降低单表数据量从而去提升sql查询效率;第四个针对热点数据可以引入更为高效的分布试数据库,比如redis、MongoDB等,他们可以很好的缓解mysql的访问压力同时还能提升数据的检索性能。
第三个点mysql的配置优化。mysql是经过互联网大厂检验过的生产级别的成熟数据库,对于mysql数据库本身的优化一般可以通过配置文件my.cnf来完成。比如说mysql5.7版本默认的最大链接数量是151个,这个值可以在my.cnf中修改;第二个binlog日志默认是不开起,我们也可以在这个文件中去修改开启,第三个是缓存池Bufferpool默认大小配置等,而这些配置一般是和用户的安装环境以及使用场景有关系,因此这些配置官方只会提供一个默认的配置,具体的情况还是要有使用者去根据实际情况去修改
SQL优化可以分为三个步骤,第一个是慢SQL的定位和排查,可以通过慢查询日志和慢查询日志工具分析,得到有问题的SQL列表;第二个是执行计划分析,针对慢SQL可以使用关键字explain来去查看当前sql的执行计划,重点关注type、key、rows、filter等字段,从而定位该SQL执行慢的根本原因,在针对性的优化;第三个使用show profile工具分析SQL语句资源消耗形况,可以用于SQL调优的测量,在当前会话中,该工具默认是关闭状态,打开后会保存最近15次的运行结果,针对运行慢的SQL通过该工具可以得到SQL执行过程中所有资源的开销情况,比如说IO开销,CPU开销、内存开销等为搜索字段创建索引
避免使用select *,列出需要查询的字段
垂直分割分表
选择正确的存储引擎
Redis
https://www.bilibili.com/video/BV1Jj411D7oG?t=8.4
网络
八股:
https://xiaolincoding.com/network/
https://blog.csdn.net/Royalic/article/details/119985591
TCP/IP协议簇各层作用
应用层负责处理应用程序的逻辑
传输层为两台主机上的应用程序提供端到端(end to end)的通信【TCP message segment、UDP datagram】
网络层实现了数据包的路由和转发【IP datagram】
数据链路层实现了网卡接口的网络驱动程序,以处理数据在物理媒介(比如以太网、令牌环等)上的传输。不同的物理网络具有不同的电气特性,网络驱动程序隐藏了这些细节,为上层协议提供一个统一的接口。【frame】
数据链路层(驱动程序)封装了物理网络的电气细节;网络层封装了网络连接的细节;传输层则为应用程序封装了一条端到端的逻辑通信链路,它负责数据的收发、链路的超时重连等。
HTTP(s)
1. http协议
报文结构
《计算机网络》P271
《Linux高性能服务器》P65
请求报文

响应报文

安全方面
一般通过BP抓一个包测试SQL注入,注入点包括路径、请求消息体、Cookie
可以修改Origin和X-Forwarded-For、Referer来绕过过滤
不足:
通信使用明文(不加密),内容可能会被窃听 → 加密
不验证通信方的身份,因此有可能遭遇伪装 → 认证
无法证明报文的完整性,所以有可能已遭篡改 → 完整性保护
2. https
由于HTTP明文传输且不对数据进行完整性检测,所以才会用HTTPS,HTTPS可以基于SSL和TLS
HTTPS实现了以下的安全特征
客户端与服务器之间的双向身份认证
客户端与服务器在传输HTTPS数据之前需要对双方的身份进行认证,认证过程通过交换各自的X.509数字证书的方式实现
传输数据的机密性
通信的以下部分将被加密保护
浏览器请求的服务端文档的URL
浏览器请求的服务端文档内容
用户在浏览器端填写的表单内容
浏览器和服务器之间传递的Cookie
HTTP消息头
传输数据的完整性检验
通过消息验证码(MAC)的方式对传输数据进行数字签名,实现了数据的完整性检验
HTTPS的不足
加密解密过程复杂,导致访问速度慢
加密需要认向证机构付费
整个页面的请求都要使用HTTPS
HTTPS协议可能会有哪些风险
证书的作用
3.SSL/TLS
《计算机网络安全》 P120
SSL/TLS基于TCP协议(提供可靠的数据流服务,不需要考虑超时和数据重传问题),位于TCP/IP层和应用层之间,将传输的数据分割成带有报文头和密码学保护的记录
提供的服务具有三个特性
保密性 → 对称加密
认证性 → 非对称加密
完整性 → Hash
两层协议
发送时,接收上层应用层消息,分段成可管理的块,可选择的压缩数据,应用MAC(hash),加密,添加一个头部,并将结果传给TCP
收到数据时,解密、验证、解压缩、重组后交给高层
SSL记录层上有三个高层协议,SSL握手协议、SSL密码修改协议和SSL报警协议
握手协议:允许服务器和客户端彼此认证对方,在应用协议发出或接收第一个数据之前协商加密算法和加密密钥
利用非对称加密交换密钥,利用对称加密交换报文
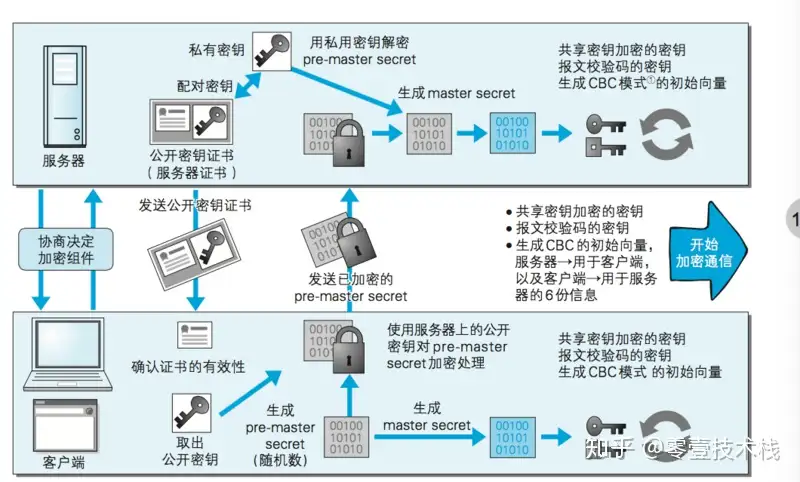
HTTPS握手过程
浏览器将自己支持的一套加密规则发送给网站。
服务器获得浏览器公钥网站从中选出一组加密算法与HASH算法,并将自己的身份信息以证书的形式发回给浏览器。证书里面包含了网站地址,加密公钥,以及证书的颁发机构等信息。
浏览器获得服务器公钥获得网站证书之后浏览器要做以下工作: (a). 验证证书的合法性(颁发证书的机构是否合法,证书中包含的网站地址是否与正在访问的地址一致等),如果证书受信任,则浏览器栏里面会显示一个小锁头,否则会给出证书不受信的提示。 (b). 如果证书受信任,或者是用户接受了不受信的证书,浏览器会生成一串随机数的密码(接下来通信的密钥),并用证书中提供的公钥加密(共享密钥加密)。 (c) 使用约定好的HASH计算握手消息,并使用生成的随机数对消息进行加密,最后将之前生成的所有信息发送给网站。
浏览器验证 -> 随机密码 服务器的公钥加密 -> 通信的密钥 通信的密钥 -> 服务器网站接收浏览器发来的数据之后要做以下的操作: (a). 使用自己的私钥将信息解密取出密码,使用密码解密浏览器发来的握手消息,并验证HASH是否与浏览器发来的一致。 (b). 使用密码加密一段握手消息,发送给浏览器。
服务器用自己的私钥解出随机密码 -> 用密码解密握手消息(共享密钥通信)-> 验证HASH与浏览器是否一致(验证浏览器)
TCP/UDP
1.报文结构
TCP

UDP

2.三次握手和四次挥手
《计算机网络》P238
假设A运行TCP客户端程序,B运行TCP服务器程序,最初两端的TCP进程都处于CLOSED状态。
B:先创建传输控制块TCB(Transmission Control Block),准备接受客户端进程的连接请求【LISTEN】
A:先创建传输控制块TCB,然后向B发出连接请求报文段,其中首部中同步位SYN=1,同时选择一个初始序号seq = x【SYN-SENT】
TCP规定,SYN报文段(即SYN=1的报文段)不能携带数据,但要消耗掉一个序号
B:收到连接请求报文段,如同意建立连接,则向A发送确认。在确认报文段中应把SYN位和ACK位都置1,确认号是ack = x + 1,同时选择一个初始序号set = y【SYN-RCVD】
不能携带数据,同样要消耗掉一个序号
A:收到B的确认后,还要向B给出确认。确认报文段ACK置1,确认号ack = y + 1,而自己的序号seq = x + 1。【ESTABLISHED】
TCP报文规定,ACK报文段可以携带数据,但如果不携带数据则不消耗序号,这种情况下,下一个数据报文段的序号仍然是seq = x + 1。
B:收到A的确认后,进入【ESTABLISHED】
TCP四次挥手
数据传输结束后,通信的双方都可以释放连接。现在A和B都处于【ESTABLISHED】状态
A:发出连接释放报文段,并停止再发送数据,主动关闭TCP连接。A把连接释放报文段首部终止控制位FIN置1,其序号seq = u,它等于前面已传送过的数据的最后一个字节的序号加1,等待B的确认【FIN-WAIT-1】
FIN报文段即使不携带数据,也消耗掉一个序号
B:收到连接释放报文段后立即发出确认,确认号是ack = u + 1,而这个报文段自己的序号是v,等于B前面一传送过的数据的最后一个字节的序号加1【CLOSED-WAIT】
此时TCP服务器进程应通知高层应用进程,因而从A到B这个方向的连接就释放了,这是TCP连接处于半关闭状态,即A已经没有数据要发送了,但B若发送数据,A仍要接收
A:收到来自B的确认后,进入【FIN-WAIT-2】,等待B发出的连接释放报文段
B:若已经没有要向A发送的数据,其应用进程就通知TCP释放连接。这是B发出的连接释放报文段必须使FIN=1。现假定B的序号为w(在半关闭状态B可能又发送了一些数据),B还必须重复上次已经发送过的确认号ack = u + 1,此时B进入【LAST-ACK】状态,等待A的确认
A:收到B的连接释放报文段后,必须对此发出确认。在确认段中把ACK置1,确认号ack = w + 1,而自己的序号是seq = u + 1(前面发送的FIN报文段要消耗掉一个序号),然后进入【TIME-WAIT】状态,此时TCP连接还没有释放掉,必须经过时间等待计时器设置的时间2MSL后,A才进入到【CLOSED】状态。
时间MSL叫做最长报文段寿命(Maximum Segment Lifetime),RFC793建议设置为2分钟
3.TCP状态机
《计算机网络》P242
《Linux高性能服务器》P41
4.TCP和UDP的区别
https://zhuanlan.zhihu.com/p/108579426
区别 | TCP | UDP |
|---|---|---|
可靠性 | 可靠 | 不可靠 |
连接性 | 面向连接 | 无连接 |
报文 | 面向字节流 | 面向报文 |
效率 | 传输效率低 | 传输效率高 |
双工性 | 全双工,仅支持点对点 | 一对一、一对多、多对一、多对多 |
流量控制 | 滑动窗口 | 无 |
拥塞控制 | 慢开始、拥塞避免、快重传、快恢复 | 无 |
传输速度 | 慢 | 快 |
应用场景 | 对效率要求低,对准确性要求高或者要求有连接的场景 | 对效率要求高,对准确性要求低 |
5.TCP服务特点
Linux高性能服务编程 P30
TCP协议相对于UDP协议的特点是:面向连接、字节流和可靠传输
面向连接:使用TCP协议通信的双方必须先建立连接,然后才能开始数据的读写
双方都必须为该连接分配必要的内核资源,以管理连接的状态和连接上数据的传输。TCP连接是全双工的,即双方的数据读写可以通过一个连接进行。完成数据交换后,通信双方都必须断开连接以释放系统资源。
字节流:应用程序对数据的发送和接收是没有边界限制的
字节流服务和数据报服务的区别对应到实际编程中体现为通信双方是否必须执行相同次数的读、写操作。
当发送端应用程序连续执行多次读写操作时,TCP模块先将这些数据放入TCP发送缓冲区中。当TCP模块真正开始发送数据时,发送缓冲区中这些等待发送的数据可能被封装成一个或多个TCP报文段发出。因此,TCP模块发送出的TCP报文段的个数和应用程序执行的写操作次数之间没有固定的数量关系。
当接收端收到一个或多个TCP报文段后,TCP模块将它们携带的应用程序数据按照TCP报文段的序号依次放入TCP接收缓冲区中,并通知应用程序读取数据。接收端应用程序可以一次性将TCP接收缓冲区中的数据全部读出,也可以分多次读取,这取决于用户指定的应用程序读缓冲区的大小。因此,应用程序执行的读操作次数和TCP模块接收到的TCP报文段个数之间也没有固定的数量关系。
综上,发送端执行的写操作次数和接收端执行的读操作次数之间没有任何关系。
(UDP:发送端应用程序每执行一次写操作,UDP模块就将其封装成一个UDP数据报并发送之,接收端必须及时针对每一个UDP数据报执行读操作【recvfrom】,否则会发生丢包,如果用户没有指定足够的应用程序缓冲区来读取UDP数据,则UDP数据将被截断)
可靠传输
首先,TCP协议采用发送应答机制,及发送端发送的每个TCP报文段都必须得到接收方的应答,才认为这个TCP报文段传输成功;其次,TCP协议采用超时重传机制,发送端在发送一个TCP报文之后启动定时器,,如果在定时时间内未收到应答,它将重新发送该报文段。最后,因为TCP报文段最终是以IP数据报发送的,而IP数据报到达接收端可能乱序、重复,所以TCP协议还会对接收到的TCP报文段重排、整理,再交给应用层。
6.TCP如何保证数据的可靠传输?
TCP(传输控制协议)是一种面向连接的协议,它在网络通信中起着重要的作用。TCP通过以下几种方式来保证数据的可靠性:
序列号与确认:发送方将每个数据包按顺序编号,并等待接收方的确认。接收方收到数据包后会发送一个确认消息,指示下一个期望接收的序列号。如果发送方没有收到确认消息或收到了错误的确认消息,它会重新发送该数据包。
数据校验和:TCP使用校验和机制来检测数据在传输过程中是否发生了错误。发送方在发送数据前计算出一个校验和,并在接收方接收数据后重新计算一次。如果两次计算的校验和不一致,则说明数据在传输过程中发生了错误,接收方会要求发送方重新发送数据。
确认超时与重传:TCP使用超时机制来判断数据包是否丢失。如果发送方在一定时间内没有收到确认消息,它会假设数据包丢失,并重新发送该数据包。接收方收到重复的数据包时会丢弃掉重复的数据,以防止应用层接收到重复的数据。
滑动窗口:TCP使用滑动窗口机制来实现流量控制和拥塞控制。滑动窗口的大小由接收方动态调整,它限制了发送方在没有接收到确认消息之前可以发送的数据量。这样可以防止发送方发送过多的数据导致接收方无法处理。
连接管理:TCP使用三次握手建立连接和四次挥手关闭连接的方式来确保可靠性。在建立连接时,双方会交换一些控制信息,以确认彼此的状态。在关闭连接时,双方会进行确认,以确保双方都已经完成数据传输。
总结起来,TCP通过序列号与确认、数据校验和、确认超时与重传、滑动窗口和连接管理等机制来保证数据的可靠性。这些机制确保了数据包按顺序到达、没有被篡改或丢失,并且避免了网络拥塞和流量过载的问题。
IP
1.报文结构
《Linux高性能服务器》P18
2. 局域网内数据包怎么转发的,不同局域网间数据包是怎么转发的
在局域网(LAN)内部,数据包转发是通过交换机(Switch)完成的。
局域网内部数据包转发:当一台计算机A发送数据包到同一局域网内的另一台计算机B时,计算机A会将数据包发送到交换机。交换机根据数据包中的目标MAC地址,查找其存储在交换表(MAC地址表)中的对应端口,并将数据包只转发到目标MAC地址所对应的端口,从而实现局域网内部的数据包传递。交换机能够识别和学习不同计算机的MAC地址,建立并维护一个MAC地址表,以便进行正确的转发。
不同局域网间数据包转发:当一台计算机A发送数据包到另一个不同局域网内的计算机B时,数据包需要经过路由器(Router)来实现跨网段的数据传输。计算机A首先将数据包发送到与其相连的本地路由器。该路由器根据路由表中的信息,确定数据包的下一跳(下一个路由器或目标网络),然后将数据包转发到下一跳的路由器。这个过程会重复发生,直到数据包到达目标局域网内的路由器,然后再被转发给目标计算机B。
(路由器或主机)数据包转发子模块执行的操作
Linux高性能 p26
检查数据报头部的TTL值,如果TTL值是0,则丢弃该数据报。
检查数据报头部的严格源路由选项。如果该选项被设置,则检测数据报的目标地址是否是本机的某个IP地址。如果不是,则发送一个ICMP源站选路失败报文给发送端。
如果有必要,则给源端发送一个ICMP重定向报文,已告诉它一个更合理的下一条路由器。
将TTL值减一
处理IP头部选项
如果有必要,则执行IP分片操作
转发,判断目标IP是否是自己的直连网段,如果是,查找路由表发送给对应交换机;如果不是,查找路由表找到下一跳地址,如果需要填充MAC地址则广播ARP请求。
ARP解析过程
DNS协议
协议构成
解析过程
面试题:
拓哥 https://top.interviewguide.cn/
在浏览器中输入URL会发生什么
1、查浏览器缓存,看看有没有已经缓存好的,如果没有
2 、检查本机host文件,
3、调用API,Linux下Socket函数 gethostbyname
4、向DNS服务器发送DNS请求,查询本地DNS服务器,这其中用的是UDP的协议
5、如果在一个子网内采用ARP地址解析协议进行ARP查询如果不在一个子网那就需要对默认网关进行DNS查询,如果还找不到会一直向上找根DNS服务器,直到最终拿到IP地址(全球400多个根DNS服务器,由13个不同的组织管理)
6、这个时候我们就有了服务器的IP地址 以及默认的端口号了,http默认是80 https是 443 端口号,会,首先尝试http然后调用Socket建立TCP连接,
7、经过三次握手成功建立连接后,开始传送数据,如果正是http协议的话,就返回就完事了,
8、如果不是http协议,服务器会返回一个5开头的的重定向消息,告诉我们用的是https,那就是说IP没变,但是端口号从80变成443了,好了,再四次挥手,完事,
9、再来一遍,这次除了上述的端口号从80变成443之外,还会采用SSL的加密技术来保证传输数据的安全性,保证数据传输过程中不被修改或者替换之类的,
10、这次依然是三次握手,沟通好双方使用的认证算法,加密和检验算法,在此过程中也会检验对方的CA安全证书。
11、确认无误后,开始通信,然后服务器就会返回你所要访问的网址的一些数据,在此过程中会将界面进行渲染,牵涉到ajax技术之类的,直到最后我们看到色彩斑斓的网页
密码学
《计算机网络安全》
P18
对称加密算法
非对称加密算法
操作系统
基础
内存页大小是
4KB磁盘扇区是
512kBMMU(Memory Management Unit)可以实现虚拟内存向物理内存的映射,也可以设置修改内存访问级别
寄存器大小是
4B
C/C++基础
面试高频问题 https://space.bilibili.com/393625476/video
strcpy和memcpy的区别 https://blog.csdn.net/weixin_38169413/article/details/88380877
内存泄漏
new出来的内存没有通过delete合理的释放掉
https://blog.csdn.net/u013569930/article/details/123539426?spm=1001.2014.3001.5502
在类的构造函数和析构函数中,new/delete没有配对使用
在释放指向数组的指针时使用delete,没有使用delete[]
没有将基类的析构函数定义为虚函数,当基类指针指向子类对象时,如果基类的析构函数不是虚函数,那么子类的析构函数不会被调用
没有对嵌套的对象指针进行嵌套释放
浅拷贝导致其中一个对象内的动态内存泄漏
联合体、结构体、类
区别
联合体的成员共享同一块内存,只能同时存储其中一个成员的值。联合体的大小由最大的成员决定
++和*的优先级
https://blog.csdn.net/baidu_38495508/article/details/122408385 最后一个错了
优先级
前缀++和 * 优先级相同
后缀 ++ 优先级 大于 *
几种情况
*p++ ① 执行p++,但是返回的是原来的p ②解引用p原来位置的元素 *p ③p的指针实际上++
(*p)++ ①*p ②值++
*(p++) 同*p++
*++p 优先级相同,从右往左执行,① 地址++,返回p本身 ② 解引用
++*p 优先级相同,从右往左执行, ① 解引用 ② 值++
[]、()、.、->运算符优先级最高,结合方向从左到右
内存对齐
为什么要内存对齐
大部分处理器一般会以双字节,4字节,8字节,16字节甚至32字节为单位来存取内存,上述这些存取单位称为内存存取粒度,通过内存对齐可以提高内存读取效率。
内存对齐规则
(1) 结构体第一个成员的偏移量(offset)为0,以后每个成员相对于结构体首地址的 offset 都是该成员大小与有效对齐值中较小那个的整数倍,如有需要编译器会在成员之间加上填充字节。
(3) 结构体的总大小为 有效对齐值 的整数倍,如有需要编译器会在最末一个成员之后加上填充字节。
有效对其值:是给定值#pragma pack(n)和结构体中最长数据类型长度中较小的那个。有效对齐值也叫对齐单位。
每个特定平台上的编译器都有自己的默认“对齐系数”(也叫对齐模数)。gcc中默认#pragma pack(4),可以通过预编译命令#pragma pack(n),n = 1,2,4,8,16来改变这一系数。
malloc、new、::operator new的区别
malloc、new 和 ::operator new 是在 C++ 中用于动态分配内存的三种不同方式,它们之间有以下区别:
语法和用法:
malloc是 C 语言中的函数,用于分配指定大小的内存块。它的语法是void* malloc(size_t size),返回一个void*指针。new是 C++ 中的运算符,用于创建对象并分配内存。它的语法是new Type(单个对象)或new Type[N](对象数组),返回一个指向分配内存的对象指针。::operator new是 C++ 中的底层内存分配函数,用于分配指定大小的内存块。它的语法是void* operator new(size_t size),返回一个void*指针。
类型安全:
malloc返回的是void*指针,需要进行显式的类型转换,并且无法调用对象的构造函数。new在分配内存的同时会调用对象的构造函数,确保对象的正确初始化,并返回指向对象的指针。::operator new只负责分配内存,不会调用对象的构造函数,需要显式调用对象的构造函数来初始化对象。
内存分配失败的处理:
malloc在分配内存失败时返回NULL,需要手动检查返回值来处理内存分配失败的情况。new在分配内存失败时会抛出std::bad_alloc异常,可以使用异常处理机制来处理内存分配失败的情况。::operator new在分配内存失败时返回NULL,需要手动检查返回值来处理内存分配失败的情况。
内存释放的方式:
malloc分配的内存需要使用free函数进行释放,语法是void free(void* ptr)。new分配的内存需要使用delete运算符进行释放,语法是delete ptr(单个对象)或delete[] ptr(对象数组)。::operator new分配的内存需要使用::operator delete函数进行释放,语法是void operator delete(void* ptr)。
需要注意的是,new 和 delete 运算符在分配和释放内存时还会调用对象的构造函数和析构函数,以执行对象的初始化和清理操作。而 malloc 和 ::operator new 只负责内存的分配和释放,不会自动调用对象的构造函数和析构函数。因此,在使用 malloc 或 ::operator new 分配内存时,需要手动调用对象的构造函数和析构函数来进行对象的初始化和清理。
继承
菱形继承(多重继承)的弊端
子类继承两份相同的数据,导致存储空间浪费、二义性
虚继承实现原理
虚继承通过虚基类指针和虚基类表实现,每个虚继承的子类都有一个虚基类指针(占用一个指针的存储空间,4字节)和虚基类表(不占用类对象的存储空间),通过虚基类表指针(virtual base table pointer,vbptr)指向了一个虚基类表(virtual table),虚表中记录了虚基类与本类的偏移地址;通过偏移地址,这样就找到了虚基类成员
class Sheep size(12):
+---
0 | {vbptr}
+---
+--- (virtual base Animal)
4 | m_Age
8 | m_Sex
+---
Sheep::$vbtable@:
0 | 0
1 | 4 (Sheepd(Sheep+0)Animal)
vbi: class offset o.vbptr o.vbte fVtorDisp
Animal 4 0 4 0
class SheepTuo size(16):
+---
0 | +--- (base class Sheep)
0 | | {vbptr}
| +---
4 | +--- (base class Tuo)
4 | | {vbptr}
| +---
+---
+--- (virtual base Animal)
8 | m_Age
12 | m_Sex
+---
SheepTuo::$vbtable@Sheep@:
0 | 0
1 | 8 (SheepTuod(Sheep+0)Animal)
SheepTuo::$vbtable@Tuo@:
0 | 0
1 | 4 (SheepTuod(Tuo+0)Animal)
vbi: class offset o.vbptr o.vbte fVtorDisp
Animal 8 0 4 0多态
https://www.bilibili.com/video/BV1nu411W7LR?t=2.3
静态多态:重载和模板,在编译期编译器确定函数地址
动态多态:通过继承重写基类的虚函数实现的多态,在运行时在虚函数表中确定调用函数的地址
多态的表现:基类类型指针指向基类调用基类方法,指向派生类调派生类
多态实现的原理:虚函数表、虚函数指针
C++对象模型
在C++中,类内的成员变量和成员函数分开存储
只有非静态成员变量才属于类的对象上
空对象占用内存空间为1Byte,因为C++编译器会给每个空对象分配一个字节的空间,为了区分空对象占内存的位置,每个空对象也应该有一个独一无二的内存地址
动态多态实现原理
多态满足条件
有继承关系
子类重写父类中的虚函数(函数返回值类型 函数名 参数列表 完全一致称为重写)
多态使用:父类指针或引用指向子类对象
当一个类中声明了虚函数时,编译器会为该类生成一个虚函数表(virtual function table,简称vftable),用于存储该类中虚函数的地址。当创建一个类的对象时,该对象中会包含一个指向该类的虚函数表的指针(简称vfptr),用于动态绑定调用虚函数。在程序运行期间,当调用一个虚函数时,会根据该对象的vptr指向的虚函数表来确定调用的虚函数的地址,从而实现运行时多态性。
虚函数表是在编译时创建的,它是与类本身相关的,而不是与类的实例相关
在一个类的继承体系中,派生类没有覆盖基类的虚函数,那么派生类也会继承基类的虚函数表,但这个虚函数表中的指针都指向基类的虚函数实现
多态的优点
代码组织结构清晰
可读性强
利于扩展以及维护(符合开闭原则)
常量指针和指针常量
const int * p = &a; 常量指针,变形 int const * p = &a;
int * const p = &a; 指针常量
“前不后变”
限制对象只能建立在堆上或栈上
https://blog.csdn.net/qq_42698422/article/details/106932482
建立类只能建立在堆上(设置析构函数为Protected)
class A
{
protected:
A(){}
~A(){}
public:
static A* create()
{
return new A();
}
void destory()
{
delete this;
}
}; 只能建立在栈上(重载new函数设为私有)
class A
{
private:
void* operator new(size_t t){} // 注意函数的第一个参数和返回值都是固定的
void operator delete(void* ptr){} // 重载了new就需要重载delete
public:
A(){}
~A(){}
};内存操作的陷阱
内存分配失败,还去使用。比如
malloc/new分配内存可能会失败内存分配虽然成功,但是尚未初始化就使用
内存分配虽然成功并且已经初始化,但操作越过了内存的边界
忘记了
delete/free内存,造成了内存泄漏使用
free或delete释放了内存之后,未立即将指针设置为NULL,产生”悬空指针“,此时若再使用该指针,指针返回的值为垃圾值
//1,2
int * p = NULL;
p = (int *)malloc(sizeof(int));
if (p == NULL)
{
/* ... */
}
/*初始化为0*/
memset(p, 0, sizeof(int));//3
int * p = NULL;
p = (int *)malloc(3 * sizeof(int));
if (p == NULL)
{
/* ... */
}
/* 初始化为0 */
memset(p, 0, sizeof(int));
std::cout << p[4] << std::endl;指针和引用的区别
定义和性质不同
指针是一个变量,存储的是一个地址;引用是原变量的一个别名,跟原来的变量实质上是一个东西,是语法糖
指针可以有多级,引用只能是一级
指针可以在定义的时候不初始化,引用必须在定义的时候初始化
指针可以指向NULL,引用不可以为NULL
sizeof的运算结果不同
自增运算意义不同
作为参数传递时的意义不同
指针参数传递本质上是值传递,传递的是一个地址值,在栈中开辟内存空间以存放实参值,实参值拷贝过去,因此存放的是一个副本,从而函数对形参的任何操作都不会影响实参的值
引用参数传递过程中,被调函数的形参也作为局部变量在栈中开辟了内存空间,但是这时存放的是实参变量的地址,因此函数对形参的任何操作都会影响实参的值
指针
悬挂指针和野指针有什么区别?
野指针:未初始化的指针叫做野指针。⽤ gcc -Wall 编译, 会出现 used uninitialized 警告。
悬空指针:当指针指向的对象被释放,但是该指针没有任何改变,以至于其仍然指向已经被回收的内存地址,这种情况下的指针叫做悬空指针
回调函数
typedef int (callBack)(const void *buffer,size_t size,char *p_out);请帮我解释这段代码
这段代码定义了一个函数指针类型 callBack,该函数指针指向一个接受三个参数的函数:
一个指向 const void 类型的缓冲区的指针 buffer。
一个表示缓冲区大小的参数 size,类型为 size_t。
一个指向 char 类型的输出缓冲区的指针 p_out。
该函数返回一个 int 类型的值,用于指示函数执行的成功或失败状态。
通过这个函数指针类型,可以定义一个函数指针变量,用于指向任何符合该类型声明的函数。这种方式通常用于回调函数,即传递一个函数指针作为参数给另一个函数,以便让另一个函数在适当的时候调用该回调函数。callBack前面可不可以加*号
是的,可以在 callBack 前面加上 * 符号来声明一个函数指针。事实上,typedef int (callBack)(const void *buffer,size_t size,char *p_out); 中的 callBack 已经是一个函数指针类型,所以 *callBack 和 callBack 是等价的,都可以用来声明一个函数指针变量。
例如,可以使用以下代码声明一个名为 func_ptr 的函数指针变量:
callBack *func_ptr;
或者使用以下代码声明一个等价的函数指针变量:
*callBack func_ptr;
无论使用哪种方式声明函数指针变量,它们都指向一个具有相同参数和返回类型的函数。为什么callBack加不加*都是代表函数指针
在C语言中,函数名被视为指向函数代码的指针。因此,在声明函数指针时,我们可以直接使用函数名,也可以使用星号(*)来明确声明指向函数的指针。
因此,下面这两种声明是等价的:
typedef int (*callBack)(const void *buffer, size_t size, char *p_out);
callBack funcPtr1;
和
typedef int callBack(const void *buffer, size_t size, char *p_out);
callBack *funcPtr2;
在第一个声明中,"callBack"被定义为指向函数的指针类型。"funcPtr1"是一个指向函数的指针,其指向的函数需要具有与"callBack"类型定义相同的参数列表和返回值类型。
在第二个声明中,"callBack"被定义为一个函数类型。通过在声明函数指针时使用星号(*),我们明确表示这是一个指向函数的指针。"funcPtr2"是一个指向函数的指针,其指向的函数需要具有与"callBack"类型定义相同的参数列表和返回值类型。
因此,无论是使用"callBack"还是"callBack*"都可以定义一个函数指针类型。static
static线程安全
https://blog.csdn.net/leigelaile1/article/details/121492055
explicit
C++中提供了explicit关键字,在构造函数声明的时候加上explicit关键字,能够禁止隐式转换
C++重载
C语言中为什么没有重载?
编译器在编译.c文件时,生成的符号表里函数的样子大致为_函数名,此时同名函数不同参数会发生符号冲突,产生二义性
C++重载的底层原理
编译器在编译.cpp文件时,生成的符号表里函数的样子大致为_函数名 + 参数类型的缩写
比如compute函数
C编译器下生成的符号表为_Compute;
C++为_ComputeGPU...Func...和_ComputeCPU...Func...
C++编译器默认给一个类添加什么函数
默认构造函数(无参,函数体为空)
默认析构函数(无参,函数体为空)
拷贝构造函数(浅拷贝)
拷贝赋值运算符重载
移动构造函数
移动赋值运算符重载
左值引用和右值引用
解释一下左值和右值
https://www.cnblogs.com/zhangyi1357/p/16018810.html
左值(L-value):
左值是一个标识具有持久性、可以被引用或取地址的表达式。它通常对应着内存中的一个位置,可以作为赋值的目标。
左值可以是变量、对象、数组元素等,也可以是通过引用获得的对象。例如,int a = 10; 中的 a 就是一个左值。
左值可以出现在赋值语句的左边或右边,可以作为函数参数进行传递,可以被修改或读取。
右值(R-value):
右值是一个临时的、没有命名的表达式,它可能不具有持久性,并且不能被引用或取地址。
右值可以是字面量、临时对象或者表达式的计算结果。例如,int b = 20 + 30; 中的 20 + 30 就是一个右值。
右值一般只能出现在赋值语句的右边,可以作为函数的返回值,但不能被修改。简单说就是可以取地址的,有名字的就是左值,反之,不能取地址的,没有名字的就是右值
通常字面量都是一个右值,除字符串字面量以外(长的字符串会保存在堆中)
左值引用和右值引用
左值引用只能接受左值,右值引用只能接受右值,但是右值引用本身是个左值。
移动语义
指将一块内存单元(可以是变量的内存单元也可以是临时对象的内存单元)从一个对象转移到另一个对象。std::move实现原理
std::move是一个类型转换器,仅仅将实参类型转为右值引用,使得发生移动拷贝或移动赋值行为,这要求实参对应的类型实现了移动构造函数或移动赋值函数,否则依然是深拷贝的过程
template <typename T>
typename remove_reference<T>::type&& move(T&& t)
{
return static_case<typename remove_reference<T>::type&&>(t);
}STL
迭代器种类
种类 | 功能 | 支持运算 |
|---|---|---|
输入迭代器 | 对数据的只读访问 | 只读,支持++、==、!= |
输出迭代器 | 对数据的只写访问 | 只写,支持++、!= |
前向迭代器 | 读写操作,并能向前推进迭代器 | 读写,支持++、==、!= |
双向迭代器 | 读写操作,并能向前和向后操作 | 读写,支持++、--,==、!= |
随机访问迭代器 | 读写操作,可以以跳跃的方式访问任意数据,功能最强的迭代器 | 读写,支持++、--、==、!= [n]、±n、<、<=、>、>= |
enable if
// STRUCT TEMPLATE enable_if
template<bool _Test,
class _Ty = void>
struct enable_if
{ // type is undefined for assumed !_Test
};
template<class _Ty>
struct enable_if<true, _Ty>
{ // type is _Ty for _Test
using type = _Ty;
};模板特化
https://www.bilibili.com/video/BV1Co4y1P7gc?t=2.1
万能引用(引用折叠)的规则
遇左则左,如果存在右值引用,结果就是右值引用
万能引用的形式必须是T && 或者 auto &&,如果在推导过程中出现中间过程,则不是一个万能引用,如
void foo(std::vector<T> && t) {} //形参不是T&&,因此编译器无法将其看作一个万能引用个人理解:万能引用依赖于模板函数的自动类型推导
如何实现一个函数既能传递左值又能传递右值?
在C++11及以后的版本中,引入了右值引用和std::move操作来更好地处理这类问题。你可以通过使用模板和“完美转发”技术来定义一个函数,使其既能接受左值也能接受右值。
下面是如何实现这样一个函数模板的例子:
#include <utility>
template<typename T>
void myFunction(T&& arg)
{
// 在此处,arg始终是个左值,无论T是左值引用还是右值引用
// 为了保持arg的原来状态(左值或者右值),我们需要再次使用std::forward进行转发
someOtherFunction(std::forward<T>(arg));
}上述代码中的 myFunction 可以接受任意左值或者右值。并且它会保存原始参数的性质(左值或者右值)并将其传递给 someOtherFunction。这就是所谓的完美转发,因为我们不仅将参数的值转发,而且还将参数的性质(左值/右值/const等)也一并转发。
注意,在使用 std::forward 进行转发时,必须使用和模板参数名完全相同的形式,即 "T&&" 。只有这样才能真正实现完美转发。
如果你在实际编程中需要定义这样的函数,准确地理解和使用右值引用和std::forward就非常重要了。
注意使用万能引用接收参数的时候,要用到模板自动类型推导,不能显式的指定类型
int a = 0;
myFunction(a);
myFunction(10);完美转发
https://zhuanlan.zhihu.com/p/50816420
利用引用折叠和强制类型转换,保持参数原来的引用类型
template<typename T>
void PrintType(T&& param){ actualRun(std::forward(param); }std::move实现原理
template <class T>
typename std::remove_reference<T>::type&& move(T&& arg) noexcept
{
return static_cast<typename std::remove_reference<T>::type&&>(arg);
}std::forward实现原理
template <class T>
T&& forward(typename std::remove_reference<T>::type& arg) noexcept
{
return static_cast<T&&>(arg);
}
//右值引用
template <class T>
T&& forward(typename std::remove_reference<T>::type&& arg) noexcept
{
//如果是左值引用,就会触发静态断言,提示用户使用错误
static_assert(!std::is_lvalue_reference<T>::value, "bad forward");
//强制转换为右值引用类型,以确保参数的值类别不变
return static_cast<T&&>(arg);
}sort排序
copy实现
关键字
typedef
C语言typedef的用法 http://c.biancheng.net/view/298.html
using和typedef https://www.bilibili.com/video/BV1Qh4y1G7Bs?t=304.0
typedef 是 C 和 C++ 编程语言中的一个关键字,它允许程序员为已有的数据类型定义一个新的名称。其语法如下:
typedef existing_type new_type_name;其中,existing_type 是已有的数据类型(比如 int 或 float),而 new_type_name 是程序员为该数据类型定义的新名称。
使用 typedef 定义新的数据类型名称可以使代码更加清晰易懂,也可以使代码更易于维护。例如,可以使用 typedef 定义一个新的数据类型名称来表示一个复杂的数据结构,这样就可以在代码中更方便地使用该数据结构,而不必每次都写出完整的类型名称。
typedef struct node * link如何解释
在C语言中,typedef可以用来为已有的数据类型定义一个新的名字。在这里,typedef struct node * link定义了一个新的类型名字link,它是一个指向struct node结构体的指针类型。
换句话说,我们可以使用link来代替struct node *作为指向结构体node的指针类型。例如,如果我们有一个函数的参数是一个指向struct node的指针,我们可以将它定义为link类型,这样就可以更方便地使用:
void my_function(link my_node_ptr) {
// do something with my_node_ptr
}上面的代码与下面的代码等价:
void my_function(struct node * my_node_ptr) {
// do something with my_node_ptr
}使用typedef可以简化代码,提高代码的可读性和可维护性。
typedef struct{} sqStack是什么意思
通过typedef给这个结构体起了一个别名(sqStack)。
这个别名(sqStack)可以在代码的其他部分用来定义变量类型,比如:
typedef struct{} sqStack;
sqStack stack1, stack2;这里,sqStack被定义为一个没有成员的结构体,也就是说,这个结构体并不会存储任何数据。它通常用于作为栈(stack)的数据类型,因为栈并不需要存储复杂的数据结构,只需要一个能够存储元素的容器即可。
需要注意的是,虽然这个结构体没有成员,但是它的大小不为0,因为在C语言中,任何一个结构体的大小都至少为1字节。
typename
volatile
const和volatile
https://blog.csdn.net/ShenJu_DL_ShengHuo/article/details/48241217
extern
extern C
C不支持重载(符号表),不能以C++的方式进行编译
inline
noexcept
https://zhuanlan.zhihu.com/p/624737461
https://www.cnblogs.com/sword03/p/10020344.html
override和final
https://www.bilibili.com/video/BV1vu4y1o7NQ?t=15.9
const和constexpr
https://www.bilibili.com/video/BV1bV411M7Ld?t=489.5
enum和enum class
https://www.bilibili.com/video/BV17m4y1v7ZC?t=360.7
C++11新特性
C++11新特性主要包含语法改进和标准库扩充两个方面,主要包括以下:
语法改进
统一的初始化方法
C++11中,初始化列表的实用性被大大增加,可以用于任何类型对象的初始化
智能指针
shared_ptr实现
https://zhuanlan.zhihu.com/p/344953368
template<typename T>
class smart
{
private:
T* _ptr;
int* _count; //reference couting
public:
//构造函数
smart(T* ptr = nullptr) :_ptr(ptr)
{
if (_ptr)
{
_count = new int(1);
}
else
{
_count = new int(0);
}
}
//拷贝构造
smart(const smart& ptr)
{
if (this != &ptr)
{
this->_ptr = ptr._ptr;
this->_count = ptr._count;
(*this->_count)++;
}
}
//重载operator=
smart& operator=(const smart & ptr)
{
if (this->_ptr == ptr._ptr)
{
return *this;
}
if (this->_ptr)
{
(*this->_count)--;
if (*this->_count == 0)
{
delete this->_ptr;
delete this->_count;
}
}
this->_ptr = ptr._ptr;
this->_count = ptr._count;
(*this->_count)++;
return *this;
}
//operator*重载
T& operator*()
{
if (this->_ptr)
{
return *(this->_ptr);
}
}
//operator->重载
T* operator->()
{
if (this->_ptr)
{
return this->_ptr;
}
}
//析构函数
~smart()
{
(*this->_count)--;
if (*this->_count == 0)
{
delete this->_ptr;
delete this->_count;
}
}
//return reference couting
int use_count()
{
return *this->_count;
}
};unique_ptr实现
template<typename T>
class UniquePtr
{
public:
UniquePtr(T *pResource = NULL)
: m_pResource(pResource)
{
}
~UniquePtr()
{
del();
}
public:
void reset(T* pResource) // 先释放资源(如果持有), 再持有资源
{
del();
m_pResource = pResource;
}
T* release() // 返回资源,资源的释放由调用方处理
{
T* pTemp = m_pResource;
m_pResource = nullptr;
return pTemp;
}
T* get() // 获取资源,调用方应该只使用不释放,否则会两次delete资源
{
return m_pResource;
}
public:
operator bool() const // 是否持有资源
{
return m_pResource != nullptr;
}
T& operator * ()
{
return *m_pResource;
}
T* operator -> ()
{
return m_pResource;
}
private:
void del()
{
if (nullptr == m_pResource) return;
delete m_pResource;
m_pResource = nullptr;
}
private:
UniquePtr(const UniquePtr &) = delete; // 禁用拷贝构造
UniquePtr& operator = (const UniquePtr &) = delete; // 禁用拷贝赋值
private:
T *m_pResource;
};weak_ptr如何解决循环依赖问题?
没有shared_ptr中的计数器
右值引用
移动语义和完美转发
移动构造函数和移动赋值运算符
其他
nullptr
constexpr
auto自动类型推导
范围for遍历
继承构造函数
标准库扩充
无序容器
线程支持
Lambda表达式
Linux系统编程
gcc编译

编译步骤是:检查语法规范,并将C代码翻译成汇编代码
注意,带有行号的是编译阶段出错,不带行号的是汇编阶段出错
静态库和动态库
静态库和动态库区别
静态库和动态库都是常见的代码复用方式,但它们有着不同的特点和使用场景。
静态库是一种将所有需要的代码都打包在一个库文件中的方式,当程序被编译链接时,静态库的代码会被复制到可执行文件中,因此可执行文件可以独立运行,不需要依赖其他库文件。静态库的优点是使用简单,不需要额外的运行时库支持,且运行速度较快;缺点是占用磁盘空间较大,并且多个可执行文件需要使用同一个静态库时,会导致重复的代码冗余,造成资源浪费。
动态库则是一种将代码打包为库文件,并在程序运行时动态地加载的方式。当程序被编译链接时,不会将动态库的代码复制到可执行文件中,而是在程序运行时根据需要加载动态库的代码。动态库的优点是占用磁盘空间较小,多个可执行文件可以共用同一个库文件,且库文件更新时不需要重新编译可执行文件;缺点是使用相对复杂,需要在运行时动态加载库文件,且运行速度相对慢。
总的来说,静态库适合在资源充足的情况下,需要快速地打包和部署代码的场景;动态库适合在资源较少,需要实现代码共享和动态更新的场景。在实际开发中,需要根据具体的需求选择合适的库类型。
通常情况下,静态库的文件名以.a或.lib为后缀,动态库的文件名以.so或.dll为后缀。
使用简单 or 困难
运行速度快 or 慢
磁盘占用 大 or 小
是否需要额外的库支持以及代码是否冗余
制作动态库的步骤
生成位置无关的.o文件
gcc -c add.c -o add.o -fPIC
使用这个参数过后,生成的函数就和位置无关,汇编代码中挂上@plt标识,等待 动态绑定地址
使用 gcc -shared制作动态库
gcc -shared -o lib库名.so add.o sub.o div.o编译可执行程序时指定所使用的动态库。
-l:指定库名(去掉lib和.so,留中间部分)-L:指定库路径
gcc test.c -o a.out -l mymath -L ./lib -I ./inc将动态库绝对路径写入配置文件
~/.bashrc中export LD_LIBRARY_PATH=xxxx运行可执行程序./a.out
GDB
常用参数
打印Core dump
文件系统
递归遍历目录
文件描述符重定向dup2
Makefile
进程
1.进程地址空间模型

共享区是动态库加载的位置;
2.PCB进程控制块
本质是结构体,包含如下成员
进程id
进程状态: 初始态、就绪态、运行态、挂起态、终止态。
进程当前工作目录位置
文件描述符表
信号相关信息资源。
用户id和组id(ps aux 返回结果里,第二列是进程id)
3.进程控制
循环创建N个子进程
#include <stdio.h>
#include <unistd.h>
int main(int argc, char * argv[])
{
int i;
pid_t pid;
for (i = 0; i< 5; i++)
{
if (fork() == 0)
{
break;
}
}
if (i == 5)
{
sleep(5);
printf("I'm parent\n");
}
else
{
sleep(i);
printf("I'm %dth child\n", i + 1);
}
return 0;
}4.进程共享
fork完父子进程相同
.text、.data(全局变量)、.stack、.heap、环境变量、用户ID、宿主目录、进程工作目录、信号处理方式都相同,注意,是”刚fork完相同,而非共享“
不相同
进程ID、fork返回值、父进程ID、进程运行时间、定时器、未决信号集
【父子进程共享】
1.文件描述符(打开文件的结构体)
mmap建立的映射区
对于其他内容如全局变量父子进程间遵循读时共享,写时复制的原则,而不是简单的拷贝父进程
0-3G的地址空间和PCB
5.exec函数族
第一个参数相当于从哪里找什么,execlp由于默认到环境变量中找,所以第一个参数只要写找什么;第二个往后相当于完整的命令
execlp
p代表环境变量
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
pid_t pid = fork();
if (pid == -1)
{
perror("fork error");
exit(1);
}
else if (pid == 0)
{
execlp("ls", "ls", "-l", "-h", NULL);
perror("exec error");
exit(1);
}
else
{
sleep(1);
printf("I'm parent : %d\n", getpid());
}
return 0;
} execl
execl("/bin/ls", "ls", "-l", "-F", "-a", NULL);输出到文件
#include <unistd.h>
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
int fd;
fd = open("ps.out", O_WRONLY|O_CREAT|O_TRUNC, 0644);
if(fd < 0){
perror("open ps.out error");
exit(1);
}
dup2(fd, STDOUT_FILENO);
execlp("ps", "ps", "ax", NULL);
perror("execlp error");
//close(fd); //如果execl执行成功,后面的代码不会执行,现阶段借助系统的隐式回收来回收文件描述符,以后可以借助信号相关的知识
return 0;
}6.孤儿进程 僵尸进程
孤儿进程
父进程先于子进终止,子进程沦为孤儿进程,会被 init 进程领养,init进程成为子进程的父进程。
僵尸进程
子进程终止,父进程尚未对子进程进行回收,在此期间,子进称为“僵尸进程”。
kill 对其无效,因为该进程已经终止了
每个进程结束后都必然会经历僵尸态,时间长短的差别而已。
子进程终止时,子进程残留资源PCB存放于内核中,PCB记录了进程结束原因,进程回收就是回收PCB。回收僵尸进程,得kill它的父进程,让孤儿院去回收它。
孤儿进程可以是僵尸进程吗?僵尸进程可以是孤儿进程吗
孤儿进程和僵尸进程是两个不同的概念。
孤儿进程是指其父进程已经终止,但是该进程仍在运行。这种情况下,孤儿进程会被 init 进程(也就是进程号为1的进程)接管,并由其回收资源。而僵尸进程是指一个进程已经结束,但是其父进程还没有回收它的资源(包括进程描述符、部分内存和一些其他的资源),这种进程称为僵尸进程。僵尸进程占用系统资源,因此应该被及时清理。
在理论上,一个孤儿进程可能会成为僵尸进程。当孤儿进程结束时,其父进程已经不存在了,因此它的资源没有被回收,会变成僵尸进程。但是在实际情况下,孤儿进程通常会被 init 进程回收,不会变成僵尸进程。
反过来,一个僵尸进程不一定是孤儿进程。如果其父进程仍在运行,但没有回收僵尸进程的资源,那么该僵尸进程就不是孤儿进程。只有当其父进程已经终止,它才成为孤儿进程。
7.守护进程
创建会话
调用进程不能是进程组组长,该进程变成新会话首进程
该进程成为一个新进程组的组长进程
需要root权限(ubuntu不需要)
新会话丢弃原有的控制终端,该会话没有控制终端(没有办法跟用户完成交互)
该调用进程是组长进程,则出错返回(组长不能创建会话)
建立新会话时,先调用fork,父进程终止,子进程调用
setsid
pid_t setsid(void)
创建一个会话,并以自己的ID设置进程组ID,同时也是新会话的ID;成功返回调用进程的会话ID,失败返回-1,设置error
会话组组长PID、PGID、SID都相同
守护进程
概念
① daemon进程是Linux中的后台服务进程,通常独立于控制终端并周期性的等待某个事件发生或周期性的执行某一动作;②一般不与用户进行交互,不受用户登录注销影;③ 通常采用以d结尾的命名方式。
创建步骤
fock子进程,让父进程终止子进程调用
setsid()创建新会话通常根据需要
改变工作目录位置
chdir重设umask文件权限掩码
关闭/重定向文件描述符
守护进程业务逻辑
#include <stdio.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <errno.h>
#include <pthread.h>
void sys_err(const char *str)
{
perror(str);
exit(1);
}
int main(int argc, char *argv[])
{
pid_t pid;
int ret, fd;
pid = fork();
if (pid > 0) // 父进程终止
exit(0);
pid = setsid(); //创建新会话
if (pid == -1)
sys_err("setsid error");
ret = chdir("/home/itcast/28_Linux"); // 改变工作目录位置
if (ret == -1)
sys_err("chdir error");
umask(0022); // 改变文件访问权限掩码
close(STDIN_FILENO); // 关闭文件描述符 0
fd = open("/dev/null", O_RDWR); // fd --> 0
if (fd == -1)
sys_err("open error");
dup2(fd, STDOUT_FILENO); // 重定向 stdout和stderr
dup2(fd, STDERR_FILENO);
while (1); // 模拟 守护进程业务.
return 0;
}进程回收
wait
函数作用1: 阻塞等待子进程退出(可以理解为阻塞等待子进程死亡)
函数作用2: 回收子进程残留资源(清理子进程残留在内核的 pcb 资源)
函数作用3: 通过传出参数,得到子进程结束状态(退出原因)
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
#include <sys/wait.h>
int main(void)
{
pid_t pid, wpid;
int status;
pid = fork();
if(pid == -1){
perror("fork error");
exit(1);
} else if(pid == 0){ //son
printf("I'm process child, pid = %d\n", getpid());
sleep(10);
/*
这时可以用kill杀死子进程,观察情况
*/
exit(10);
} else {
//wpid = wait(NULL); //不关心进程结束原因,只回收
wpid = wait(&status); //传出参数 如果子进程未终止,父进程阻塞在这个函数上
if(WIFEXITED(status)){ //正常退出
printf("I'm parent, The child process %d exit normally\n", wpid);
printf("return value:%d\n", WEXITSTATUS(status)); //获取子进程退出状态
} else if (WIFSIGNALED(status)) { //为真说明子进程被信号终止
//获取杀死子进程的信号编号
printf("The child process exit abnormally, killed by signal %d\n", WTERMSIG(status));
} else {
printf("other...\n");
}
}
return 0;
}waitpid
pid_t waitpid(pid_t pid, int status, int options)
参数
pid:指定回收某一个子进程pid
>0: 待回收的子进程pid
-1:任意子进程
0:回收和当前调用waitpid同一个进程组的所有子进程(默认情况下,父进程和自己fork的所有子进程默认都在同一个组)
status:(传出) 回收进程的状态。
options:
WNOHANG指定回收方式为,非阻塞。
返回值:
>0 : 表成功回收的子进程 pid
0 : 函数调用时, 参3 指定了WNOHANG, 并且,没有子进程结束。
-1: 失败。errno
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/wait.h>
#include <pthread.h>
int main(int argc, char *argv[])
{
int i;
pid_t pid, wpid, tmpid;
for (i = 0; i < 5; i++) {
pid = fork();
if (pid == 0) { // 循环期间, 子进程不 fork
break;
}
if (i == 2) {
tmpid = pid;
printf("--------pid = %d\n", tmpid);
}
}
if (5 == i) { // 父进程, 从 表达式 2 跳出
sleep(5);
printf("i am parent , before waitpid, pid = %d\n", tmpid);
//wait(NULL); // 一次wait/waitpid函数调用,只能回收一个子进程.
//wpid = waitpid(-1, NULL, WNOHANG); //回收任意子进程,没有结束的子进程,父进程直接返回0
//wpid = waitpid(tmpid, NULL, 0); //指定一个进程回收, 阻塞等待
wpid = waitpid(tmpid, NULL, WNOHANG); //指定一个进程回收, 不阻塞
if (wpid == -1) {
perror("waitpid error");
exit(1);
}
printf("I'm parent, wait a child finish : %d \n", wpid);
} else { // 子进程, 从 break 跳出
sleep(i);
printf("I'm %dth child, pid= %d\n", i+1, getpid());
}
return 0;
} 循环回收多个
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/wait.h>
#include <pthread.h>
int main(int argc, char *argv[])
{
int i;
pid_t pid, wpid;
for (i = 0; i < 5; i++) {
if (fork() == 0) { // 循环期间, 子进程不 fork
break;
}
}
if (5 == i) {
while ((wpid = waitpid(-1, NULL, WNOHANG)) != -1) { //不关心回收的状态,第二个参数用NULL,然后是使用非阻塞方式,回收子进程.
if (wpid > 0) {
printf("wait child %d \n", wpid);
} else if (wpid == 0) {
sleep(1);
continue;
}
}
} else { // 子进程, 从 break 跳出
sleep(i);
printf("I'm %dth child, pid= %d\n", i+1, getpid());
}
return 0;
} 进程间通信
通信方式及函数
通信方式 | 优点 | 缺点 | 函数 |
|---|---|---|---|
管道 | 使用最简单 | 只能用在有血缘关系的两个进程之间,父子、兄弟、叔侄进程,其他的由于找不到共同的文件描述符所以不能通信 | pipe |
命名管道(fifo) | 非血缘关系间通信 | mkfifo | |
信号 | 开销最小,系统资源占用少,快 | 数据量有限,表示的数据比较单一 | |
共享区映射(mmap) | 非血缘关系间通信 | mmap | |
本地套接字(socket) | 最稳定 | 实现复杂度最高,一旦实现好了稳定性最强 |
信号
线程
1. 线程共享资源和非共享资源
共享资源
文件描述符表
每种信号的处理方式
当前工作目录
用户ID和组ID
内存地址空间
非共享资源
线程ID
处理器现场(寄存器中的值)和栈指针(内核栈)
独立的栈空间(用户空间栈)
errno变量
信号屏蔽字
调度优先级
2. 线程创建
循环回收子线程
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <pthread.h>
int var = 100;
void *tfn(void *arg)
{
int i;
i = (int)arg;
sleep(i);
if (i == 1) {
var = 333;
printf("var = %d\n", var);
return (void *)var;
} else if (i == 3) {
var = 777;
printf("I'm %dth pthread, pthread_id = %lu\n var = %d\n", i+1, pthread_self(), var);
pthread_exit((void *)var);
} else {
printf("I'm %dth pthread, pthread_id = %lu\n var = %d\n", i+1, pthread_self(), var);
pthread_exit((void *)var);
}
return NULL;
}
int main(void)
{
pthread_t tid[5];
int i;
int *ret[5]; //指针数组
for (i = 0; i < 5; i++)
pthread_create(&tid[i], NULL, tfn, (void *)i);
for (i = 0; i < 5; i++) {
pthread_join(tid[i], (void **)&ret[i]);
printf("-------%d 's ret = %d\n", i, (int)ret[i]);
}
printf("I'm main pthread tid = %lu\t var = %d\n", pthread_self(), var);
sleep(i);
return 0;
}通过线程属性设置分离态
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <errno.h>
#include <pthread.h>
void *tfn(void *arg)
{
printf("thread: pid = %d, tid = %lu\n", getpid(), pthread_self());
return NULL;
}
int main(int argc, char *argv[])
{
pthread_t tid;
pthread_attr_t attr;
int ret = pthread_attr_init(&attr);
if (ret != 0) {
fprintf(stderr, "attr_init error:%s\n", strerror(ret));
exit(1);
}
ret = pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED); // 设置线程属性为 分离属性
if (ret != 0) {
fprintf(stderr, "attr_setdetachstate error:%s\n", strerror(ret));
exit(1);
}
ret = pthread_create(&tid, &attr, tfn, NULL);
if (ret != 0) {
perror("pthread_create error");
}
ret = pthread_attr_destroy(&attr);
if (ret != 0) {
fprintf(stderr, "attr_destroy error:%s\n", strerror(ret));
exit(1);
}
ret = pthread_join(tid, NULL);
if (ret != 0) {
fprintf(stderr, "pthread_join error:%s\n", strerror(ret));
exit(1);
}
printf("main: pid = %d, tid = %lu\n", getpid(), pthread_self());
pthread_exit((void *)0);
}锁
※1.互斥锁
互斥量
#include <stdio.h>
#include <string.h>
#include <pthread.h>
#include <stdlib.h>
#include <unistd.h>
pthread_mutex_t mutex;
void err_thread(int ret, char *str)
{
if (ret != 0) {
fprintf(stderr, "%s:%s\n", str, strerror(ret));
pthread_exit(NULL);
}
}
void *tfn(void *arg)
{
srand(time(NULL));
while (1) {
pthread_mutex_lock(&mutex);
printf("hello ");
sleep(rand() % 3); /*模拟长时间操作共享资源,导致cpu易主,产生与时间有关的错误*/
printf("world\n");
pthread_mutex_unlock(&mutex);
sleep(rand() % 3);
}
return NULL;
}
int main(void)
{
srand(time(NULL));
int ret = 0, flag = 5;
pthread_t tid;
//动态初始化锁
ret = pthread_mutex_init(&mutex, NULL);
if (ret != 0)
{
err_thread(ret, "pthread_mutex_init");
}
//静态初始化锁
//pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
pthread_create(&tid, NULL, tfn, NULL);
while (flag--) {
pthread_mutex_lock(&mutex);
printf("HELLO ");
sleep(rand() % 3);
printf("WORLD\n");
pthread_mutex_unlock(&mutex);
sleep(rand() % 3);
}
pthread_cancel(tid); // 将子线程杀死,子线程中自带取消点
pthread_join(tid, NULL);
//销毁锁
pthread_mutex_destroy(&mutex);
//return 0; //main中的return可以将整个进程退出
pthread_exit(NULL);
}2.两种死锁
产生原因
对同一个互斥量反复加锁
两个线程各持有一把锁,请求另一把;
#include <stdio.h>
#include <unistd.h>
#include <pthread.h>
#if 0
int var = 1, num = 5;
pthread_mutex_t m_var, m_num;
void *tfn(void *arg)
{
int i = (int)arg;
if (i == 1) {
pthread_mutex_lock(&m_var);
var = 22;
sleep(1); //给另外一个线程加锁,创造机会.
pthread_mutex_lock(&m_num);
num = 66;
pthread_mutex_unlock(&m_var);
pthread_mutex_unlock(&m_num);
printf("----thread %d finish\n", i);
pthread_exit(NULL);
} else if (i == 2) {
pthread_mutex_lock(&m_num);
num = 33;
sleep(1);
pthread_mutex_lock(&m_var);
var = 99;
pthread_mutex_unlock(&m_var);
pthread_mutex_unlock(&m_num);
printf("----thread %d finish\n", i);
pthread_exit(NULL);
}
return NULL;
}
int main(void)
{
pthread_t tid1, tid2;
int ret1, ret2;
pthread_mutex_init(&m_var, NULL);
pthread_mutex_init(&m_num, NULL);
pthread_create(&tid1, NULL, tfn, (void *)1);
pthread_create(&tid2, NULL, tfn, (void *)2);
sleep(3);
printf("var = %d, num = %d\n", var, num);
ret1 = pthread_mutex_destroy(&m_var); //释放琐
ret2 = pthread_mutex_destroy(&m_num);
if (ret1 == 0 && ret2 == 0)
printf("------------destroy mutex finish\n");
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
printf("------------join thread finish\n");
return 0;
}
#else
int a = 100;
int main(void)
{
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
pthread_mutex_lock(&mutex);
a = 777;
pthread_mutex_lock(&mutex); //阻塞等待
pthread_mutex_unlock(&mutex);
printf("-----------a = %d\n", a);
pthread_mutex_destroy(&mutex);
return 0;
}
#endif死锁产生的四种条件
互斥条件
不剥夺条件
请求和保持条件
循环等待条件
3.读写锁
共享-独占锁,读写锁非常适合于对数据结构读的次数远大于写的情况。
三句话
① 锁只有一把
② 读共享,写独占
③ 写锁优先级高(同时争夺的时候)
/* 3个线程不定时 "写" 全局资源,5个线程不定时 "读" 同一全局资源 */
#include <stdio.h>
#include <unistd.h>
#include <pthread.h>
int counter; //全局资源
pthread_rwlock_t rwlock;
void *th_write(void *arg)
{
int t;
int i = (int)arg;
while (1) {
t = counter; // 保存写之前的值
usleep(1000);
pthread_rwlock_wrlock(&rwlock);
printf("=======write %d: %lu: counter=%d ++counter=%d\n", i, pthread_self(), t, ++counter);
pthread_rwlock_unlock(&rwlock);
usleep(9000); // 给 r 锁提供机会
}
return NULL;
}
void *th_read(void *arg)
{
int i = (int)arg;
while (1) {
pthread_rwlock_rdlock(&rwlock);
printf("----------------------------read %d: %lu: %d\n", i, pthread_self(), counter);
pthread_rwlock_unlock(&rwlock);
usleep(2000); // 给写锁提供机会
}
return NULL;
}
int main(void)
{
int i;
pthread_t tid[8];
pthread_rwlock_init(&rwlock, NULL);
for (i = 0; i < 3; i++)
pthread_create(&tid[i], NULL, th_write, (void *)i);
for (i = 0; i < 5; i++)
pthread_create(&tid[i+3], NULL, th_read, (void *)i);
for (i = 0; i < 8; i++)
pthread_join(tid[i], NULL);
pthread_rwlock_destroy(&rwlock); //释放读写琐
return 0;
}4.条件变量
※5.信号量
/*信号量实现 生产者 消费者问题*/
#include <stdlib.h>
#include <unistd.h>
#include <pthread.h>
#include <stdio.h>
#include <semaphore.h>
#define NUM 5
int queue[NUM]; //全局数组实现环形队列
sem_t blank_number, product_number; //空格子信号量, 产品信号量
void *producer(void *arg)
{
int i = 0;
while (1) {
sem_wait(&blank_number); //生产者将空格子数--,为0则阻塞等待
queue[i] = rand() % 1000 + 1; //生产一个产品
printf("----Produce---%d\n", queue[i]);
sem_post(&product_number); //将产品数++
i = (i+1) % NUM; //借助下标实现环形
sleep(rand()%1);
}
}
void *consumer(void *arg)
{
int i = 0;
while (1) {
sem_wait(&product_number); //消费者将产品数--,为0则阻塞等待
printf("-Consume---%d\n", queue[i]);
queue[i] = 0; //消费一个产品
sem_post(&blank_number); //消费掉以后,将空格子数++
i = (i+1) % NUM;
sleep(rand()%3);
}
}
int main(int argc, char *argv[])
{
pthread_t pid, cid;
sem_init(&blank_number, 0, NUM); //初始化空格子信号量为5, 线程间共享 -- 0
sem_init(&product_number, 0, 0); //产品数为0
pthread_create(&pid, NULL, producer, NULL);
pthread_create(&cid, NULL, consumer, NULL);
pthread_join(pid, NULL);
pthread_join(cid, NULL);
sem_destroy(&blank_number);
sem_destroy(&product_number);
return 0;
}Linux网络编程
套接字
server.c
#include <stdio.h>
#include <ctype.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <errno.h>
#include <pthread.h>
#define SERV_PORT 9527
void sys_err(const char *str)
{
perror(str);
exit(1);
}
int main(int argc, char *argv[])
{
int lfd = 0, cfd = 0;
int ret, i;
char buf[BUFSIZ], client_IP[1024];
struct sockaddr_in serv_addr, clit_addr; // 定义服务器地址结构 和 客户端地址结构
socklen_t clit_addr_len; // 客户端地址结构大小
bzero(&serv_addr, sizeof(serv_addr));
serv_addr.sin_family = AF_INET; // IPv4
serv_addr.sin_port = htons(SERV_PORT); // 转为网络字节序的 端口号
serv_addr.sin_addr.s_addr = htonl(INADDR_ANY); // 获取本机任意有效IP
//inet_aton("127.0.0.1",&serv_addr.sin_addr);
lfd = socket(AF_INET, SOCK_STREAM, 0); //创建一个 socket
if (lfd == -1) {
sys_err("socket error");
}
bind(lfd, (struct sockaddr *)&serv_addr, sizeof(serv_addr));//给服务器socket绑定地址结构(IP+port)
listen(lfd, 128); // 设置监听上限
clit_addr_len = sizeof(clit_addr); // 获取客户端地址结构大小
cfd = accept(lfd, (struct sockaddr *)&clit_addr, &clit_addr_len); // 阻塞等待客户端连接请求
if (cfd == -1)
sys_err("accept error");
printf("client ip:%s port:%d\n",
inet_ntop(AF_INET, &clit_addr.sin_addr.s_addr, client_IP, sizeof(client_IP)),
//inet_ntoa(clit_addr.sin_addr),
ntohs(clit_addr.sin_port)); // 根据accept传出参数,获取客户端 ip 和 port
while (1) {
ret = read(cfd, buf, sizeof(buf)); // 读客户端数据
write(STDOUT_FILENO, buf, ret); // 写到屏幕查看
for (i = 0; i < ret; i++) // 小写 -- 大写
buf[i] = toupper(buf[i]);
write(cfd, buf, ret); // 将大写,写回给客户端。
}
close(lfd);
close(cfd);
return 0;
}client.c
#include <stdio.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <errno.h>
#include <pthread.h>
#include <stdio.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#define SERV_PORT 9527
void sys_err(const char *str)
{
perror(str);
exit(1);
}
int main(int argc, char *argv[])
{
int cfd;
int conter = 10;
char buf[BUFSIZ];
struct sockaddr_in serv_addr; //服务器地址结构
serv_addr.sin_family = AF_INET;
serv_addr.sin_port = htons(SERV_PORT);
//inet_pton(AF_INET, "127.0.0.1", &serv_addr.sin_addr.s_addr);
//serv_addr.sin_addr.s_addr = inet_addr("127.0.0.1");
inet_pton(AF_INET, "127.0.0.1", &serv_addr.sin_addr);
cfd = socket(AF_INET, SOCK_STREAM, 0);
if (cfd == -1)
sys_err("socket error");
int ret = connect(cfd, (struct sockaddr *)&serv_addr, sizeof(serv_addr));
if (ret != 0)
sys_err("connect err");
while (--conter) {
write(cfd, "hello\n", 6);
ret = read(cfd, buf, sizeof(buf));
write(STDOUT_FILENO, buf, ret);
sleep(1);
}
close(cfd);
return 0;
}多线程服务器
※select
IO多路复用模型(处理的是socket建立过程,线程池处理的是业务逻辑),即响应式模型;
优缺点
缺点: ① 监听上限受文件描述符限制,最大 1024。
② 检测满足条件fd的时候,只能自己添加业务逻辑提高效率,提高了编码难度(性能并不低)。
③ 如果采用轮询的方式找返回的文件描述符,如果文件描述符跨度很大,效率会很低。→ 数组
优点: 多路IO转接中唯一一个可以跨平台的。
代码实现
server.c
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <arpa/inet.h>
#include <ctype.h>
#define SERV_PORT 6666
int main(int argc, char *argv[])
{
int i, j, n, maxi;
int nready, client[FD_SETSIZE]; /* 自定义数组client, 防止遍历1024个文件描述符 FD_SETSIZE默认为1024 */
int maxfd, listenfd, connfd, sockfd;
char buf[BUFSIZ], str[INET_ADDRSTRLEN]; /* #define INET_ADDRSTRLEN 16 */
struct sockaddr_in clie_addr, serv_addr;
socklen_t clie_addr_len;
fd_set rset, allset; /* rset 读事件文件描述符集合 allset用来暂存 */
listenfd = socket(AF_INET, SOCK_STREAM, 0);
int opt = 1;
setsockopt(listenfd, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof(opt));
bzero(&serv_addr, sizeof(serv_addr));
serv_addr.sin_family= AF_INET;
serv_addr.sin_addr.s_addr = htonl(INADDR_ANY);
serv_addr.sin_port= htons(SERV_PORT);
bind(listenfd, (struct sockaddr *)&serv_addr, sizeof(serv_addr));
listen(listenfd, 128);
maxfd = listenfd; /* 起初 listenfd 即为最大文件描述符 */
maxi = -1; /* 将来用作client[]的下标, 初始值指向0个元素之前下标位置 */
for (i = 0; i < FD_SETSIZE; i++)
client[i] = -1; /* 用-1初始化client[] */
FD_ZERO(&allset);
FD_SET(listenfd, &allset); /* 构造select监控文件描述符集 */
while (1) {
rset = allset; /* 每次循环时都从新设置select监控信号集 */
nready = select(maxfd+1, &rset, NULL, NULL, NULL); //2 1--lfd 1--connfd
if (nready < 0) {
perror("select error");
exit(1);
}
if (FD_ISSET(listenfd, &rset)) { /* 说明有新的客户端链接请求 */
clie_addr_len = sizeof(clie_addr);
connfd = accept(listenfd, (struct sockaddr *)&clie_addr, &clie_addr_len); /* Accept 不会阻塞 */
printf("received from %s at PORT %d\n",
inet_ntop(AF_INET, &clie_addr.sin_addr, str, sizeof(str)),
ntohs(clie_addr.sin_port));
for (i = 0; i < FD_SETSIZE; i++)
if (client[i] < 0) { /* 找client[]中没有使用的位置 */
client[i] = connfd; /* 保存accept返回的文件描述符到client[]里 */
break;
}
if (i == FD_SETSIZE) { /* 达到select能监控的文件个数上限 1024 */
fputs("too many clients\n", stderr);
exit(1);
}
FD_SET(connfd, &allset); /* 向监控文件描述符集合allset添加新的文件描述符connfd */
if (connfd > maxfd)
maxfd = connfd; /* select第一个参数需要 */
if (i > maxi)
maxi = i; /* 保证maxi存的总是client[]最后一个元素下标 */
if (--nready == 0)
continue;
}
for (i = 0; i <= maxi; i++) { /* 检测哪个clients 有数据就绪 */
if ((sockfd = client[i]) < 0)
continue;
if (FD_ISSET(sockfd, &rset)) {
if ((n = read(sockfd, buf, sizeof(buf))) == 0) { /* 当client关闭链接时,服务器端也关闭对应链接 */
close(sockfd);
FD_CLR(sockfd, &allset); /* 解除select对此文件描述符的监控 */
client[i] = -1;
} else if (n > 0) {
for (j = 0; j < n; j++)
buf[j] = toupper(buf[j]);
write(sockfd, buf, n);
write(STDOUT_FILENO, buf, n);
}
if (--nready == 0) /* 仅有的一个connfd已经处理完了,再次while监听就好了 */
break; /* 跳出for, 但还在while中 */
}
}
}
close(listenfd);
return 0;
}client.c
/* client.c */
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <unistd.h>
#include <arpa/inet.h>
#include <netinet/in.h>
#define MAXLINE 80
#define SERV_PORT 6666
int main(int argc, char *argv[])
{
struct sockaddr_in servaddr;
char buf[MAXLINE];
int sockfd, n;
if (argc != 2) {
printf("Enter: ./client server_IP\n");
exit(1);
}
sockfd = socket(AF_INET, SOCK_STREAM, 0);
bzero(&servaddr, sizeof(servaddr));
servaddr.sin_family = AF_INET;
inet_pton(AF_INET, argv[1], &servaddr.sin_addr);
servaddr.sin_port = htons(SERV_PORT);
connect(sockfd, (struct sockaddr *)&servaddr, sizeof(servaddr));
printf("------------connect ok----------------\n");
while (fgets(buf, MAXLINE, stdin) != NULL) {
write(sockfd, buf, strlen(buf));
n = read(sockfd, buf, MAXLINE);
if (n == 0) {
printf("the other side has been closed.\n");
break;
}
else
write(STDOUT_FILENO, buf, n);
}
close(sockfd);
return 0;
}※Epoll
IO多路复用模型,即响应式模型
非阻塞边沿触发Epoll,非阻塞指的是文件描述符,边沿触发指的是事件触发模式
server.c
#include <stdio.h>
#include <string.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <sys/wait.h>
#include <sys/types.h>
#include <sys/epoll.h>
#include <unistd.h>
#include <fcntl.h>
#define MAXLINE 10
#define SERV_PORT 8000
int main(void)
{
struct sockaddr_in servaddr, cliaddr;
socklen_t cliaddr_len;
int listenfd, connfd;
char buf[MAXLINE];
char str[INET_ADDRSTRLEN];
int efd, flag;
listenfd = socket(AF_INET, SOCK_STREAM, 0);
bzero(&servaddr, sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_addr.s_addr = htonl(INADDR_ANY);
servaddr.sin_port = htons(SERV_PORT);
bind(listenfd, (struct sockaddr *)&servaddr, sizeof(servaddr));
listen(listenfd, 20);
printf("Accepting connections ...\n");
cliaddr_len = sizeof(cliaddr);
connfd = accept(listenfd, (struct sockaddr *)&cliaddr, &cliaddr_len);
printf("received from %s at PORT %d\n",
inet_ntop(AF_INET, &cliaddr.sin_addr, str, sizeof(str)),
ntohs(cliaddr.sin_port));
flag = fcntl(connfd, F_GETFL); /* 修改connfd为非阻塞读 */
flag |= O_NONBLOCK;
fcntl(connfd, F_SETFL, flag);
///////////////////////////////////////////////////////////////////////
struct epoll_event event;
struct epoll_event res_event[10];
int res, len;
efd = epoll_create(10);
event.events = EPOLLIN | EPOLLET; /* ET 边沿触发,默认是水平触发 */
event.data.fd = connfd;
epoll_ctl(efd, EPOLL_CTL_ADD, connfd, &event); //将connfd加入监听红黑树
while (1) {
printf("epoll_wait begin\n");
res = epoll_wait(efd, res_event, 10, -1); //最多10个, 阻塞监听
printf("epoll_wait end res %d\n", res);
if (res_event[0].data.fd == connfd) {
while ((len = read(connfd, buf, MAXLINE/2)) >0 ) //非阻塞读, 轮询
write(STDOUT_FILENO, buf, len);
}
}
return 0;
}
/*
1.建立socket,获取connfd
2.设置connfd属性为非阻塞
3.将connfd加入到epoll树中,有了事件获取对应fd,读取消息
*/client.c
/* client.c */
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <arpa/inet.h>
#include <netinet/in.h>
#define MAXLINE 10
#define SERV_PORT 8000
int main(int argc, char *argv[])
{
struct sockaddr_in servaddr;
char buf[MAXLINE];
int sockfd, i;
char ch = 'a';
sockfd = socket(AF_INET, SOCK_STREAM, 0);
bzero(&servaddr, sizeof(servaddr));
servaddr.sin_family = AF_INET;
inet_pton(AF_INET, "127.0.0.1", &servaddr.sin_addr);
servaddr.sin_port = htons(SERV_PORT);
connect(sockfd, (struct sockaddr *)&servaddr, sizeof(servaddr));
while (1) {
//aaaa\n
for (i = 0; i < MAXLINE/2; i++)
buf[i] = ch;
buf[i-1] = '\n';
ch++;
//bbbb\n
for (; i < MAXLINE; i++)
buf[i] = ch;
buf[i-1] = '\n';
ch++;
//aaaa\nbbbb\n
write(sockfd, buf, sizeof(buf));
sleep(10);
}
close(sockfd);
return 0;
}select、poll和epoll之间的区别是什么?
Epoll反应堆
见常见代码,读懂即可
线程池
见常见代码,读懂即可
项目
TinySTL
描述项目经历
仿照SGI版本的STL实现的一个标准模板库,实现了一些主要容器如vector、迭代器、分配器、空间配置器、仿函数和部分算法
项目遇到什么困难?如何解决的?
项目中用到了很多不懂的知识点,如移动语义、对于平凡(非平凡)可复制赋值类型的处理
sort是怎么实现的?
主要实现了使用随机访问迭代器的
vector和deque容器的sort排序,其他容器如关联式容器本身存储的时候就是按照一定顺序存储的,list有自己的sort,整体对于快速排序进行了优化,综合了快排+插入+堆排排序三种排序,限制了递归深度和分块大小整体来说使用了内省排序(Introspective Sorting)。当数据量较大时采用Quick Sort,分段递归排序,将容器内的数据分割成有序区间。一旦分段后的数据量小于某个阀值(如16),为避免递归调用带来过大的额外负荷,改用插入排序(插入排序最好情况下时间复杂度为
O(n),擅长对相对有序的数据进行排序),而如果递归层次过深进入快排陷阱,还会改用堆排序。快速排序采用了三点取中法(
median-of-3)无监督的分割以及单边递归法减少递归的调用、从而减少了栈空间的开辟、插入排序使用了无监督的排序,不判断指针的边界,极大的提高了排序的效率
RPC
描述项目经历
RPC是一个远程过程调用架构 整体基于主从Reactor架构,主从线程都运行一个loop循环,loop中运行epoll wait函数,主线程负责监听连接事件,有连接事件后,生成子线程负责处理IO事件 封装了传输层,在连接建立后,负责sock文件描述以及buffer之间的字节流传输,以及消息对象的编解码,protobuf用来进行对象的序列化 应用层主要是对于rpc请求的逻辑处理 整个项目多处通过回调函数实现异步调用
性能?如何计算的?
项目遇到什么困难?
为什么要设置应用层buffer?
方便数据处理,特别是应用层的包组装和拆解(避免粘包)
方便异步的发送(发送数据直接塞到发送缓冲区里面,等待epoll异步去发送)
提高发送效率,多个包合并一起发送
英语
自我介绍
各位面试官您好,我叫金睿,籍贯是青岛市,中共党员。本科就读于山西大学电子商务专业,研究生就读于南京理工大学网络与信息安全专业。
本硕期间成绩优秀,连续获得学业奖学金。其中本科期间曾担任2年班级团支书,获得优秀学生干部以及优秀毕业生称号,后跨专业保研,硕士期间获得多项竞赛奖励,包括国家级一项,省市级多项,发表中文核心论文一篇,英文在投一篇,专利在投一篇,拥有网络安全管理员高级工证书、英语六级证书。
本人擅长C++ Linux编程、网络编程,熟悉网络安全基础知识,学习能力强,善于沟通。
介绍某一个地方
看图说话
介绍从事方向
遇到的最有挑战性的一件事情,如何解决的
Tip
还没有整理的
文件系统
进程间通信
信号
3.字符串和int转换 同步IO和异步IO 死锁的条件和解决方法 LRU缓存 是否存在环形列表 层序遍历二叉树 索引的存储结构,B+树的存储方式 移动语义和完美转发 观察者模式 运算符优先级
MySQL性能优化 内存泄露的原因 回调函数如何使用 lamba表达式 大数相乘
1.排序 2.select poll epoll区别 3.项目描述及遇到的问题 static 看一下线程池 看一下sort 红黑树相对于其他树的优点 设计模式 extern/extern C
严格弱序 RPC要解决一个什么问题(再好好改一下简历,想一下学到了什么东西,阻塞是怎么解决的) 交叉编译 快速排序 严格弱排序的限制 强制类型转换 底层实现 如何创建一个对象限制在堆上或者栈上 gdb单步调试 CMAKE extern C交叉编译 static 符号表 线程安全 protobuf core dump的原因
shared ptr是如何重写析构的?
如何不是子类先析构而是父类先析构会怎样(为什么要先析构子类)
并发和并行 coredump的几个原因
reactor模型
结构体和联合体区别
析构的时候先析构子类再析构父类,如果先析构父类会怎样?
因为派生类的析构函数通常依赖于基类的成员和资源,如果先析构父类,那么在派生类析构函数中使用基类的成员或资源时,这些成员或资源可能已经被释放,导致未定义的行为,C++中的析构函数是虚函数,这意味着在析构一个派生类的对象时,会先调用派生类的析构函数,然后再调用基类的析构函数。这是为了确保在析构阶段正确地释放派生类和基类的资源。